Query your application with GraphRAG
Overview
GraphRAG generates a semantic knowledge base for a CAST Imaging application. It creates embeddings of your source code and generated content, extracts business entities and their relationships, and (optionally) groups them into topics. The results are stored in the application’s Neo4j database. You can then ask conceptual and business-code questions about the application through the CAST Imaging MCP Server, which runs semantic searches over the generated knowledge graph.
The GraphRAG service is included and enabled by default in CAST Imaging 3.6.5-funcrel.
Generating the knowledge graph is done from the CAST Imaging UI (3.6.5-funcrel or above) and requires only an AI provider. Querying GraphRAG requires the CAST Imaging MCP Server 3.1.0-beta1 or above.
How it works
- Generation - you run the GraphRAG pipeline for an application from the CAST Imaging UI. The pipeline embeds the selected content, extracts entities and relationships, and optionally clusters entities into topics. The output is stored in the application’s Neo4j database.
- Retrieval - once the knowledge graph exists, an MCP-aware client (for example GitHub Copilot or Claude Desktop) queries it through the CAST Imaging MCP Server using the GraphRAG tools.
Use GraphRAG for semantic questions such as business behaviour, business rules, workflows, domain concepts, and where a feature is implemented. Use the standard CAST Imaging MCP tools for exact structural questions such as applications, objects, transactions, call chains, and quality insights.
Before you start
Make sure that:
- CAST Imaging and the target application are installed and accessible.
- The application has a configured data source.
- The GraphRAG service is running and reachable from CAST Imaging.
- Neo4j is reachable from both the GraphRAG service and the CAST Imaging MCP Server.
- An AI provider is configured in AI Settings.
- The CAST Imaging MCP Server is installed if you want to query GraphRAG from an MCP client.
Configure the AI provider
GraphRAG uses AI models in two places:
- Knowledge-base generation - configured in the CAST Imaging AI Settings and used by the GraphRAG service when the pipeline runs.
- Query-time retrieval - configured in the CAST Imaging MCP Server and used when an MCP client asks GraphRAG questions (see Query GraphRAG through the MCP Server).
The GraphRAG generation service supports the following providers and default models:
| Provider | Default completion model | Default embedding model |
|---|---|---|
| OpenAI | gpt-4o-mini |
text-embedding-3-small |
| Gemini | gemini-3.1-flash-lite |
gemini-embedding-001 |
| Vertex AI | gemini-3.1-flash-lite |
text-embedding-005 |
| Ollama | gemma3:27b |
nomic-embed-text:v1.5 |
The completion model is selected in AI Settings by entering the provider model name. The embedding model is taken from the provider default, or set with AI_EMBEDDING_MODEL in the GraphRAG service configuration.
Query-time retrieval in the MCP Server must use the same embedding provider and model family used during generation in CAST Imaging. For example, if the knowledge base was generated with OpenAI embeddings, configure the MCP Server GraphRAG embedding provider as OpenAI. Using a different provider or an incompatible embedding model can produce poor or failed semantic-search results.
The CAST Imaging UI may list additional AI providers used by other AI features. For GraphRAG generation, use one of the providers listed above. Do not select Azure AI or AWS Bedrock for GraphRAG generation unless your installed GraphRAG service version explicitly supports it.
Run GraphRAG from the UI
From the landing page select Customize the results for your chosen application:

Then choose the GraphRAG tab:
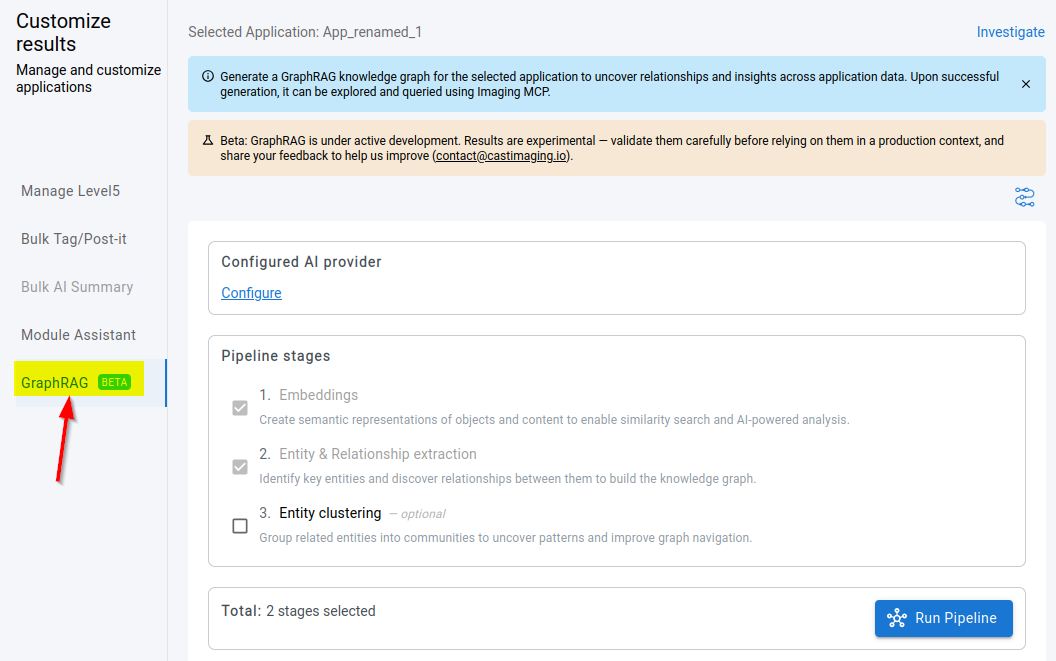
From this tab you can:
- View the configured AI provider (and navigate to AI Settings to change it).
- Run the GraphRAG pipeline, or rerun it after it completes.
- Cancel a running GraphRAG generation job.
- View the job status for the selected application.
- Choose whether to include the optional Entity clustering stage.
The tab checks that an AI provider is configured, the GraphRAG service is available, and a data source is configured for the application. If any of these are missing, the pipeline cannot be started.
Pipeline stages
| Stage | Required | Purpose |
|---|---|---|
| Embeddings | Yes | Creates semantic representations of source code and selected generated content. |
| Entity & Relationship extraction | Yes | Extracts business entities and relationships from the generated knowledge. |
| Entity clustering | Optional | Groups related entities into readable topics and themes. |
You can enable or disable only the optional Entity clustering stage. Embeddings and Entity & Relationship extraction are always run.
Run the pipeline
- Keep Entity clustering selected if you want entity topics to be generated.
- Click Run Pipeline.
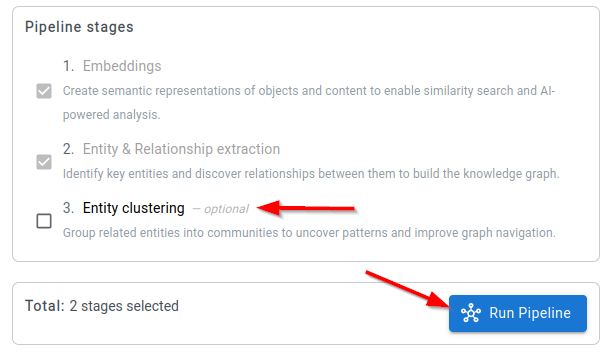
- Wait until the job status shows completed.
If generation completes with warnings, check the GraphRAG logs before relying on the results.
GraphRAG service configuration (for generation)
The GraphRAG service reads a small number of GraphRAG-specific settings from internal configuration files, notably EMBEDDING_SELECTION (which content types are embedded) and AI_EMBEDDING_MODEL (the embedding model used by the service). The AI provider, credentials, and completion model used for generation come from AI Settings in the UI. The full list of available options is as follows:
#IMAGING-GRAPH-RAG
EMBEDDING_SELECTION=source_code,technical_explanation,functionality_explanation
AI_EMBEDDING_MODEL=text-embedding-3-small
GRAPHRAG_PORT=8286
You can find these options here:
-
For CAST Imaging installed on Docker/Podman, these settings are found in the imaging-viewer .env file located in
/opt/cast/installation/imaging-viewer/.env -
For CAST Imaging installed on Microsoft Windows, these settings are found in the following file:
%PROGRAMDATA%\CAST\Imaging\CAST-Imaging-Viewer\setup-config\imaginggraphrag\app.config
Query GraphRAG through the MCP Server
GraphRAG tools are exposed through the CAST Imaging MCP Server. Enable them in the MCP Server configuration (app.config on Docker, configuration.conf on Microsoft Windows - see MCP Server installation):
GRAPHRAG_ENABLED=true
NEO4J_URL=bolt://<neo4j-host>:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=<password>
AI_PROVIDER=OpenAI
AI_EMBEDDING_MODEL=text-embedding-3-small
Provider-specific values may also be required for MCP GraphRAG retrieval:
- OpenAI:
AI_API_KEY, optionalAI_ENDPOINT - Gemini:
AI_API_KEY,AI_EMBEDDING_MODEL - Vertex AI:
AI_PROJECT_ID,AI_LOCATION,AI_CREDENTIALS_FILE,AI_EMBEDDING_MODEL - Ollama:
AI_ENDPOINT,AI_EMBEDDING_MODEL
The MCP Server also tries to read AI credentials from the CAST Imaging AI settings for the current domain. If the provider configured in CAST Imaging does not match the provider configured in the MCP Server, the MCP Server keeps its own GraphRAG AI settings.
GraphRAG MCP tools
After GRAPHRAG_ENABLED=true, the MCP Server exposes GraphRAG tools including:
graphrag_usage_guidelines- explains when to use the GraphRAG tools.graphrag_config- shows the masked GraphRAG runtime configuration.test_graphrag_connection- verifies the Neo4j and embedding configuration.get_relevant_code_context- finds code context related to a business or functional query.get_relevant_entity_clusters- finds entity topics by semantic similarity.find_entities- finds extracted entities by keyword.get_entity_clusters- lists generated entity topics.get_entity_types- lists extracted entity categories.get_entities_by_type- lists entities for a selected category.get_entity_relation_types- lists relationship types between extracted entities.get_documents_for_id- returns generated documents for a selected object, transaction, or data graph.get_prevalent_entities_in_code_structure- shows common entity topics for a transaction, data graph, or service.embed_files_as_documents- adds supplied documentation to the GraphRAG document store.
Recommended setup flow
- Configure the AI provider in AI Settings.
- Ensure the GraphRAG service is running.
- Run the GraphRAG pipeline for the application from the GraphRAG tab.
- Configure the CAST Imaging MCP Server with
GRAPHRAG_ENABLED=true. - Set the MCP Server GraphRAG provider and embedding model to match the embedding provider and model family used during generation.
- Run
test_graphrag_connectionfrom your MCP client. - Ask GraphRAG questions through your MCP client.
Troubleshooting
| Problem | What to check |
|---|---|
| The GraphRAG tab is disabled | Confirm that the GraphRAG service is running and its health endpoint is reachable. |
| Run Pipeline is blocked | Confirm that AI settings and the application data source are configured. |
| The pipeline fails immediately | Check Neo4j connectivity, AI credentials, provider support, and the GraphRAG service logs. |
| GraphRAG MCP tools are not visible | Set GRAPHRAG_ENABLED=true in the MCP Server and restart it. |
| MCP semantic search returns poor results | Confirm that the MCP provider and embedding model match the embedding provider/model family used during generation. |
| The MCP connection test fails | Check NEO4J_URL, the Neo4j credentials, the AI provider credentials, and AI_EMBEDDING_MODEL. |
Key rules
- Configure the generation model in the CAST Imaging AI Settings.
- Configure the query-time embedding model in the CAST Imaging MCP Server.
- Keep the MCP retrieval embedding provider/model family aligned with the embeddings created during generation.
- Run GraphRAG generation before using the GraphRAG MCP search tools.
- Use GraphRAG for semantic and business-code questions; use the standard CAST Imaging tools for exact structural exploration.