Qualification specifics
What you need to know about how a C/C++ project is built
Understanding how a C or C++ project is compiled and linked is the best way to configure analysis settings properly.
Build process
A C/C++ project is something that is used to generate one of these three artifacts:
- Static library (.lib, .a)
- Dynamic library (.dll, .so)
- Executable program (.exe)
The nature of the generated artifact does not matter much, but the notion of a project is nevertheless important, because it tells us what should be grouped into an Analysis Unit. A project is also useful to identify what the different options are that were used to compile the code and that are also required to analyze it correctly.
Unfortunately, there is not one standardized build system, or one project format for C++, but many different systems (autoconf, cmake, makefiles, vcxproj, xcodeproj…). And each of these systems is highly configurable, which make automatically retrieving information in those projects a very hard task. So, you have to understand better what a project does before you can configure an analysis.
The project build process is based on the following steps:
- Source code preprocessing: Each source code file (.c, .cpp, .cxx, .cc…) is processed to include additional lines of code coming from other files (typically header files: .h, .hh, .hpp, .tpp, .inl) and to generate the complete source code, aka the preprocessed source file. Note that a header file can be included in other header files.
- Compilation: Each preprocessed source file is compiled into an object file (.o, .obj).
- Link-edition: All relevant object files are linked together to produce the final artifact.
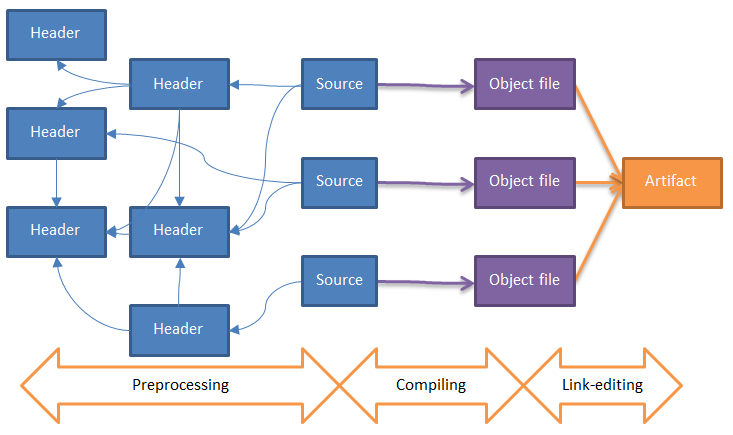
The critical step in a C/C++ source code analysis is the step related to the source code preprocessing. The reasons are as follows:
This step of the build process uses the content of the source files, but is also very dependent on various compiler options and system options. These must be set to the same value in source code analysis settings as they have during compilation. A small issue in option management can cascade and lead to a failure in header inclusion that will lead to missing macros which will cause the analyzer to have input code totally different from what it should have. We can try to be robust against small errors, but we can’t replace missing or corrupt data. This means that even if the analysis does not end in error, in case of a bad configuration, the results may be meaningless.
Header files
One of the basic rules of the C and C++ languages, is that you must first mention something before you can use it. For instance:
int f(int i)
{ return fibonacci(i);} // Incorrect, at this point in code, the function fibonacci is not known
int fibonacci(int i) // even if it is defined just after
{/* ... we define it here ... */}
The following code corrects the issue:
int fibonacci(int i)
{/* ... we define it here ... */}
int f(int i)
{ return fibonacci(i);} // Correct, at this point in code, the function fibonacci is known
If we just want to use a function defined in a third-party library, we still need to know about it:
int fibonacci(int i); // Not defined, just declared
int f(int i)
{ return fibonacci(i);} // Correct, at this point in code, the function fibonacci is known
.h files are not considered as “source code” files by CAST and as such are not automatically analyzed. If the location of the .h files is included in the relevant Analysis Unit (Include Path option) then any .h files that are referenced in application source code (.c/.cpp etc.) will be included in the analysis.
Include path
The following syntax is used in source code to textually include the content of a source file inside another source file:
// Inside file Source.cpp
##include "MyHeader.h"
When the user includes a file in another, he usually does not specify the full path of the included file, because he wants his projects to be movable to different folders. Instead, he specifies a relative path, but relative to what?
The complete rules are complex, and can vary between different compilers. But basically, each compiler has an ordered list of Include Paths that will be used as possible roots. If the code contains #include “a/b.h”, and the include path lists contains c:\folder1 and c:\folder2, the compiler will first search for a file named c:\folder1\a\b.h, and if it does not find it, will search for c:\folder2\a\b.h.
The CAST AIP environment profiles for some well-known compilers already define some include paths that include the system headers provided with the compiler. However, this requires the corresponding compiler to be installed on the analysis machine. If your compiler is not listed, you may consider defining your own profile.
The best practice is to deliver the content of the include path at the same time as the rest of the analysis. Creating a self-consistent package ensures that your analysis will generate the same correct outputs on every computer.
C/C++ is a case sensitive language, therefore it is important to ensure that:
- include directives are in lowercase - i.e. #include (the analyzer will ignore include directives using uppercase (#INCLUDE) or a mixture of lower and uppercase (#Include))
- header file extensions are referenced in the correct case otherwise
the analyzer will ignore them. E.g. if the file is called:
- header.h, it should be referenced as #include “header.h”
- header.H, it should be referenced as #include “header.H”
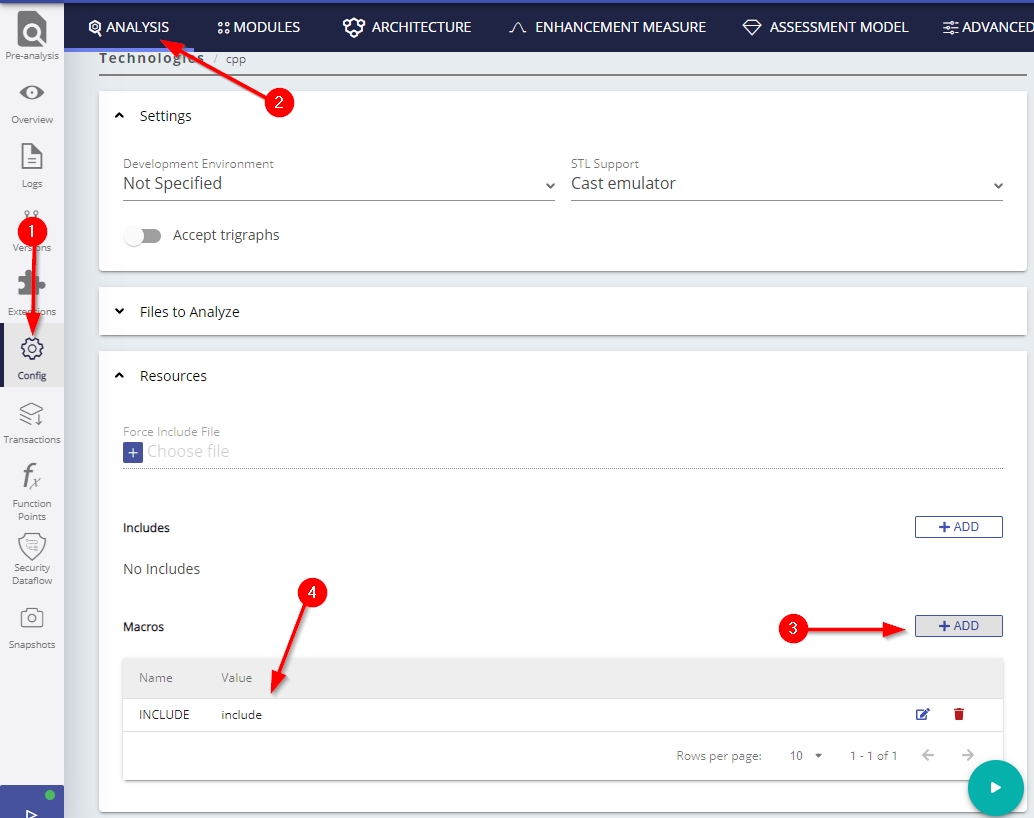
If your include statements use uppercase or a mixture of lower and uppercase, it is possible to manually create a macro in CAST Console to workaround this. For example if you are using #INCLUDE, you can create a macro as follows - this will force CAST to treat #INCLUDE as #include:
Macros
In addition to including header files, the preprocessor has another feature: It can define macros. Almost any word that you see in a C++ normal can be:
- Either a normal word, that will be directly interpreted by the C++ compiler
- Or a macro, that will be replaced by something else before being transferred to the C++ compiler
##define FOO bar;
int FOO = 12;
// This code is strictly equivalent to:
int bar = 12;
There is no way to know if a word denotes a macro or not, except reading all the code before the word is used (including the relevant headers) and searching for a #define that matches this word.
Macros can be used for many purposes in a C or C++ program. They can be used to define constants, or function-like structures, but they can also have an impact on what code will be compiled, and what code will be skipped. They are very often used to obtain a unique source code base that can adapt to several environments (different OS, different compilers, different versions of third party software etc.).
There are three ways to define macros:
- Each compiler defines a set of hard-coded macros, possibly dependent on compiler options (for instance, the macro NDEBUG will be defined if the compiler generates optimized code)
- It’s possible to pass macros as compiler options on the command line (-DMACRO=2 usually defines the macro MACRO with a value of 2)
- The source code defines the macro itself, through the #define directive.
When you define a macro, you give it a name, and a replacement string. The replacement string is optional and a macro can be empty. These empty macros are often used with #ifdef and #ifndef directives. These directives test if a macro has been defined, whatever its value.
Usually, in a real source code application, most of the macros will be defined in the source code, but how they are defined may depend on the value of a few configuration macros.
##ifdef WINDOWS // If the macro WINDOWS is defined (whatever its value)
// This include would fail on unix
#include <Windows.h>
#define PAUSE Sleep(1000)
else
// And this one would fail on Windows
#include <unistd.h>
// Not the same function, not the same unit for the parameter
#define PAUSE sleep(1)
##endif
void f()
{ PAUSE; } // We use the macro
The analyzer needs, as configuration, the macros defined by the first two methods (but not by the third method, they are already provided by the source code). In the previous example, to select the right case, you need to decide whether the macro WINDOWS should be defined or not for your analysis, but the macro PAUSE should not be defined in the analysis options.
Assembly organization
By identifying the assemblies and their properties and dependencies, you will obtain the organization of the source code, which you can use to organize the analysis units and the main input for their configuration. An assembly is a binary file that corresponds either to a library or to an executable. We don’t analyze assemblies. In order to do a proper analysis, we need to know how the source code is organized into assemblies.
When the customer provides the source code, he/she often provides a whole system that includes several assemblies. In some cases, the system can even have several hundred assemblies. Each individual source file typically belongs to one assembly. It can also belong to none or several assemblies. Included files are usually shared across assemblies.
Based on the fact that the C / C++ Analyzer works like a compiler and a compiler treats one assembly at a time, you must keep in mind that:
- You will need to create one Analysis Unit per assembly. Also, you should not have the source code of several assemblies in a single Analysis Unit, otherwise, you may have ambiguities when assemblies implement artifacts of the same type and name (especially for functions). This rule could be ignored in cases where CAST is implemented exclusively for the CAST Engineering Dashboard AND when the risk of ambiguity is very low.
- You will have to determine which source files should be used. Sometimes, based on the Operating System (see above), we may have to purposely ignore files. Although this type of situation is less common, its practice has to be addressed with customers who are using CAST to generate precise blueprints.
You should ask the customer how assemblies are built (i.e. which source code to use, and their dependencies). In many cases, each assembly is built from files contained in dedicated folders. In situations where information regarding the build-process is missing, you can refer to the build files for guidance. C/C++ code is often built using a generic mechanism instrumented by such files: usually makefiles on UNIX systems and vcproj files on Windows. When applications are built using simple makefiles, it is generally possible to figure out how the system is compiled. When makefiles are too complex you should also ask for help from an expert in this field.
Database access API
By identifying if and through which API the C/C++ code accesses databases, we can collect additional information that will be used to configure the analyzers and that will affect resolution of links to database artifacts.
For assemblies containing references to database artifacts, you need to primarily identify:
- Which databases the C/C++ code relies on as well as what releases or versions of the aforementioned databases are being used: this information should be provided by the customer. If it is not possible for you to get this information from the customer, you should take the conservative position that any C/C++ code can access any database item in all the database schema provided along with the source code.
- By what means the client code interacts with the database:
- Through embedded SQL (like PRO*C): in this case, the code contains statements beginning with the words EXEC SQL and ending with a semi-colon, with some SQL code between.
- Using the Database standard API (like OCI or OCCI for Oracle,
ODBC for SQLServer, CT-LIB for Sybase…).
- For OCI (for Oracle8 and later), you will find lots of functions prefixed by OCI.
- For SQLServer and DB2, (which use the same ODBC API), you can find functions prefixed with SQL (such as SQLConnect).
- For Sybase, functions are prefixed by db (such as dbopen,), bcp, cs, and _ct_.
Note that the database standard API can be referenced directly in the assembly code, or through a library used by the assembly. In fact, when you have a library that contains calls to DB APIs, you should consider that any other assembly depending on it could also use the database standard API (i.e. indirectly).
Note that some applications can use both embedded SQL and database APIs.
Dynamic code assessment
By determining the existence of dynamic code, you will determine whether you will need to create Reference Pattern jobs to add links and augment known dependencies between assemblies. Sometimes the C/C++ code dynamically loads libraries and gets pointers on functions from the library and then executes them. This type of situation requires additional settings, as we will see later.
To recognize dynamic code use, you need to search the source code for the system function calls that are used to load or find DLLs, and find functions in the DLLs:
- On Windows, the system functions to load/get a DLL are LoadLibrary, LoadLibraryEx, GetModuleHandle, GetModuleHandleEx. The system function to get a pointer to a function (i.e the exported-function address retriever) is GetProcAddress.
- On (most) UNIX, the load-library system function is called dlopen. The exported-function address retriever system function is dlsym. The loaded code can be either a third party library or another assembly to analyze. You can figure this out by looking at the names of the library dynamically loaded using LoadLibrary, LoadLibraryEx, or dlopen. If it is more complicated than just names, then ask the customer to see which libraries may be loaded. If you cannot get the info, consider that it may load analyzed code.
Where the loaded code belongs to the code you are analyzing, you must consider that the loading assembly is dependent (see Assembly organization and sources above) on any assembly it may load.