Packaging, delivering and analyzing source code
Introduction
Summary: This document provides information about how to package, deliver and analyze your source code with the SQL Analyzer extension. This documentation is valid for all 2.x and 3.x releases of the extension.
DDL extraction
Before you can use the extension, you may need to use a third-party DDL extractor for your RDBMS and generate one or several *.sql files containing the required DDL. In other words, you need to “export” the database schema with a tool that generates DDL from the database or at least have DDL scripts that can be used to re-build the database. This export should contain exclusively *.sql files which can then be delivered via the CAST Delivery Manager Tool.
Please note that the analyzer is not able to follow the chronology of the DDL script. In other words, we do not guarantee that files will be analyzed in the same order as the creation, modification date or versioning.
What about superfluous clauses exported in your SQL files?
When performing the DDL extraction, CAST recommends that you DO NOT export storage definitions or any other superfluous clauses in your SQL files. All minor changes in the exported SQL files (e.g.: Engine for MariaDB or even the collation) will have an impact on the analysis results: i.e. objects will be marked as updated between successive analyses.
Therefore CAST’s recommendation is to extract the SQL in the same manner, with the same tool, and using the same options that will extract unchanged objects.
How to extract data using third-party tools
The information will be extracted with DDL/DLM data formats. You need to use third-party tools to have these data, and most of the time they will be operate by the DBA. This is a non-exhaustive list. For general extraction you can also consider http://www.sql-workbench.net/dev-download.html.
| RDMS | Sources |
|---|---|

|
CAST documentation: SQL Analyzer - postgreSQL schema export or extraction as operator See also http://stackoverflow.com/questions/1884758/generate-ddl-programmatically-on-postgresql |

|
http://stackoverflow.com/questions/6597890/how-to-generate-ddl-for-all-tables-in-a-database-in-mysql |

|
CAST documentation: SQL Analyzer - MariaDB and MySQL DDL example export or extraction |

|
http://sqlitebrowser.org/ (export database function) |
|
CAST documentation: SQL Analyzer - generate DDL for a Db2 database |
|
CAST documentation: SQL Analyzer - Generate DDL for a Microsoft SQL database |
|
CAST documentation: SQL Analyzer - Generate DDL for a specific Oracle schema See also, Oracle official documentation:
|



Data export like files
Data export like files should be excluded from analysis. A data export like file is a DML file having more then 80% of INSERT … VALUES () , INSERT …. SELECT statements from the total number of DML statements.
File size limitations
When choosing to package .SQL files, please be aware that we highly recommend avoiding packaging single .SQL files that are over 128MB (classed by Microsoft as “gigantic”). The smaller the file, the faster the analysis. If you find that you are having trouble generating .SQL files that are smaller than 128MB, here are some tips:
- Separate DDL from DML and generate .SQL files for each
- If DDL are DML are connected, add dependencies between DML and DDL (DML as client). Keep only useful DML, for example, do not “generate data” if you generate your objects: generate data should be deactivated wherever possible. Data export like files should be never analyzed.
- No need to keep TCL/DCL (see definition here : https://explainjava.com/dml-ddl-dcl-tcl-sql-commands/ ) as these are not analyzed.
If your files are still Gigantic split them as follows:
- Group them by schema/database
- Group them DDL type: CREATE TABLES, CREATE VIEW, CREATE etc.
- Group them by feature: group of tables, views, procedures dedicated to a specific functionality
Oracle Application like specific case
If your database is an Oracle Application like, you should not analyse full sources.
Reduce the SQL analyzed files and analysis scope by answering to the following questions :
- The SQL code you prepare to analyse is developed by you ?
- If is the case, add-it
- The code you prepare to analyse is necessary to have transactions ?
- If is the case, add-it but ignore all quality rules calculated on the object
- The client code (Java, JCL, etc) is linked to an Oracle object that
is not developed by you ?
- If is the case, add-it but ignore all quality rules calculated on the object
How to re-use a previous extraction made with the CAST Database Extractor
SQL Analyzer is able to read and analyze the output of the CAST Database Extractor aka src and uaxDirectory files.
Packaging and delivery
Create a new Version

Create a new Package for your *.sql files using the Files on your file system option
Enter a name for the Package and then define the root folder in which your .sql files are stored

Multiple schema / database
When you will analyse multiple schema / database that are not linked with each other, put them in different analysis unit. Putting them together could impact negatively the analysis performances.
E.g.: add 4 packages for the following 4 folders because:
Z:\CAST\deploy\ApplicationName\ApplicationCode\userschemaZ:\CAST\deploy\ApplicationName\ApplicationCode\adminschemaZ:\CAST\deploy\ApplicationName\ApplicationCode\advisorschemaZ:\CAST\deploy\ApplicationName\ApplicationCode\webschema
Run the Package action
The CAST Delivery Manager Tool will not find any “projects” related to the .sql files - this is the expected behaviour. However, if your source code is part of a larger application (for example a JEE application), then other projects may be found during the package action. The CAST Delivery Manager Tool, should, however, identify the .sql files:

Deliver the Version
Analyzing
Using the CAST Management Studio:
Accept and deploy the Version in the CAST Management Studio
No Analysis Units will be created automatically relating to the .sql files - this is the expected behaviour. However, if your .sql files are part of a larger application (for example a JEE Application), then other Analysis Units may be created automatically:

Add a new Analysis Unit specifically for your SQL Script files
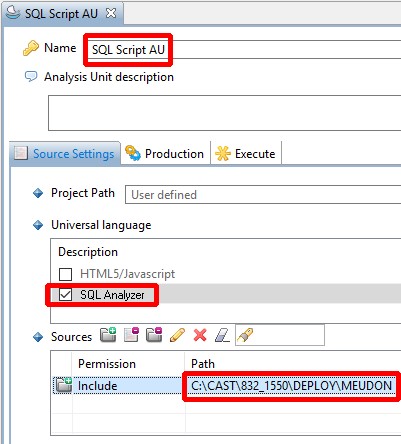
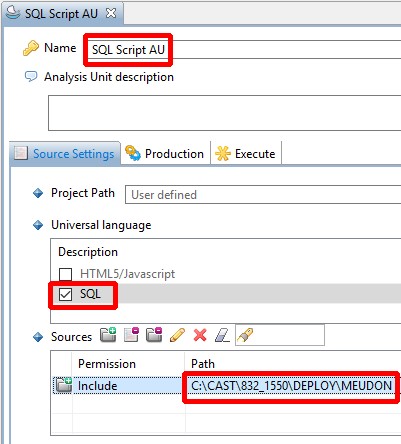
In the Current Version tab, add a new Analysis Unit specifically for your SQL Script files, selecting the Add new Universal Analysis Unit option:
- Edit the new Analysis Unit and configure in the Source Settings
tab:
- a name for the Analysis Unit
- ensure you tick the SQL Analyzer (version 2.0 only) or SQL (version ≥ 2.1) option
- define the location of the deployed SQL script files (the CAST Management Studio will locate this automatically in the Deployment folder):
| version 2.0 only | version ≥ 2.1 |
|---|---|
|
|
Multiple schema / database
When you will analyse multiple schema / database that are not linked with each other, put them in different analysis unit. Putting them together could impact negatively the analysis performances.
E.g.: add 4 analysis units for the following 4 folders:
userschema analysis unit for Z:\CAST\deploy\ApplicationName\ApplicationCode\userschema adminschema analysis unit for Z:\CAST\deploy\ApplicationName\ApplicationCode\adminschemaadvisorschema analysis unit for Z:\CAST\deploy\ApplicationName\ApplicationCode\advisorschemawebschema analysis unit for Z:\CAST\deploy\ApplicationName\ApplicationCode\webschema
Run a test analysis on the Analysis Unit before you generate a new snapshot.
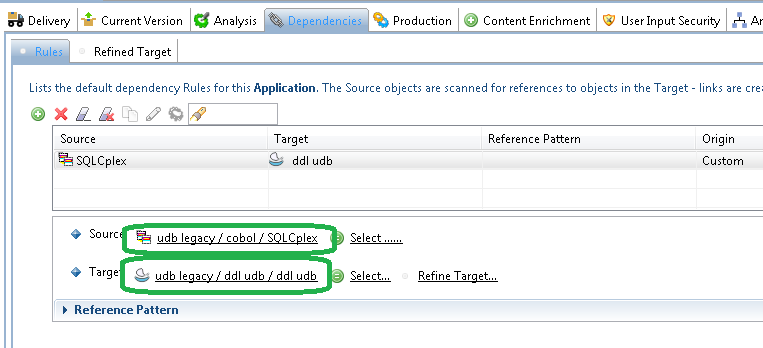
Add dependencies between client technologies (Java, C#, Mainframe etc…) to that Analysis Unit in order to get client to server links