Apache Spark JDBC - 1.0
Extension ID
com.castsoftware.java.spark
What’s new?
See Apache Spark JDBC - 1.0 - Release Notes for more information.
Description
Apache Spark is an open-source unified analytics engine for large-scale data processing. This extension provides support for Apache Spark JDBC connections in Java. Spark SQL is a component on top of Spark Core where data source options of JDBC can be set using read and write methods.
In what situation should you install this extension?
If your Java application contains Apache Spark JDBC API related source code and you want to view these object types and their links, then you should install this extension. More specifically the extension will identify:
- “callLinks” from Java methods to Apache Spark JDBC Objects
Technology support
Apache Spark
The following Apache Spark releases are supported by this extension:
| Release | Supported | Supported Technology |
|---|---|---|
| 2.0 and above | ✔️ | Java |
Compatibility
This extension is compatible with:
| CAST Imaging Core release | Supported |
|---|---|
| 8.3.x | ✔️ |
Download and installation instructions
For JEE applications using Apache Spark JDBC, the extension will be automatically installed by CAST Console. This is in place since October 2023.
For upgrade, if the Extension Strategy is not set to Auto update, you can manually install the extension using the Application - Extensions interface.
What results can you expect?
Objects
The following objects are displayed in CAST Enlighten
| Icon | Type Description | When is this object created ? |
|---|---|---|
|
Spark JDBC Read | an object is created for each database table name found in DataFrameReader api and resolved in a JDBC method call |
|
Spark JDBC Write | an object is created for each database table name found in DataFrameWriter api and resolved in a JDBC method call |
|
Spark JDBC SQL Query | an object is created for each SQL query found and resolved in a JDBC method call |
|
Spark JDBC Unknown SQL Query | an object is created for SQL query found and the exact query cannot be resolved |
Links
| Link Type | Caller type | Callee type | API's supported |
|---|---|---|---|
| callLink | Java method | Apache Spark JDBC object (Spark JDBC Read or Spark JDBC Write or Spark JDBC SQL Query or Spark JDBC Unknown SQL Query) |
Apache Spark APIsorg.apache.spark.sql.DataFrameReader.jdbc org.apache.spark.sql.DataFrameWriter.jdbc org.apache.spark.sql.DataFrameReader.load org.apache.spark.sql.DataFrameWriter.save org.apache.spark.sql.SQLContext.jdbc org.apache.spark.sql.SQLContext.load |
| useLink | Spark JDBC SQL Query | Table, View | Created by SQL Analyzer when DDL source files are analyzed |
| callLink | Spark JDBC SQL Query | Procedure | |
| useLink | Spark JDBC SQL Query | Missing Table | Created by Missing tables and procedures for JEE extension when the object is not analyzed |
| callLink | Spark JDBC SQL Query | Missing Procedure |
Code Examples
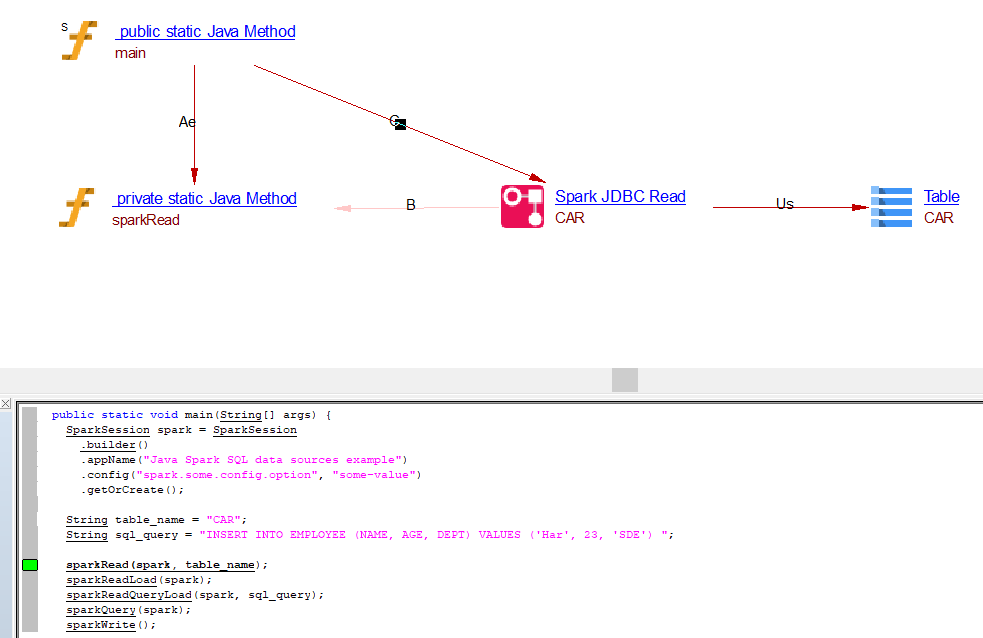
Read Operation
Read operation through .jdbc() API
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL data sources example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
String table_name = "CAR";
sparkRead(spark, table_name);
spark.stop();
}
private static void sparkRead(SparkSession spark, String table_name) {
Properties connectionProperties = new Properties();
connectionProperties.put("user", "username");
connectionProperties.put("password", "password");
Dataset<Row> jdbcDF = spark.read()
.jdbc("jdbc:postgresql:dbserver", table_name, connectionProperties);
}
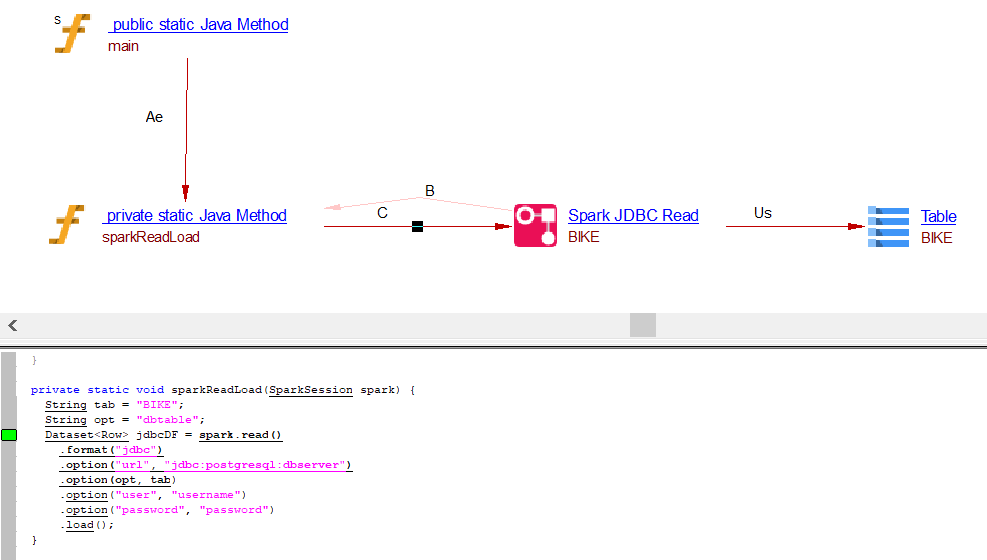
Read operation through .load() API
using dbtable
providing table name as dbtable
private static void sparkReadLoad(SparkSession spark) {
String tab = "BIKE";
String opt = "dbtable";
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option(opt, tab)
.option("user", "username")
.option("password", "password")
.load();
}
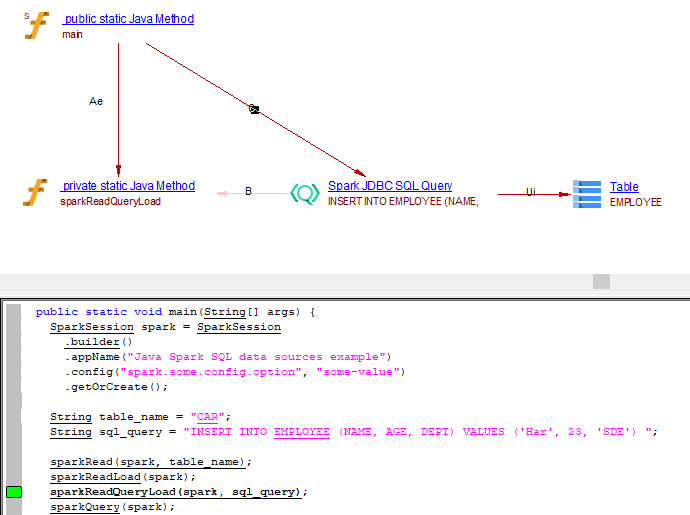
providing query as dbtable
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL data sources example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
String sql_query = "INSERT INTO EMPLOYEE (NAME, AGE, DEPT) VALUES ('Har', 23, 'SDE') ";
sparkReadQueryLoad(spark, sql_query);
spark.stop();
}
private static void sparkReadQueryLoad(SparkSession spark, String sql_query) {
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", sql_query)
.option("user", "username")
.option("password", "password")
.load();
}
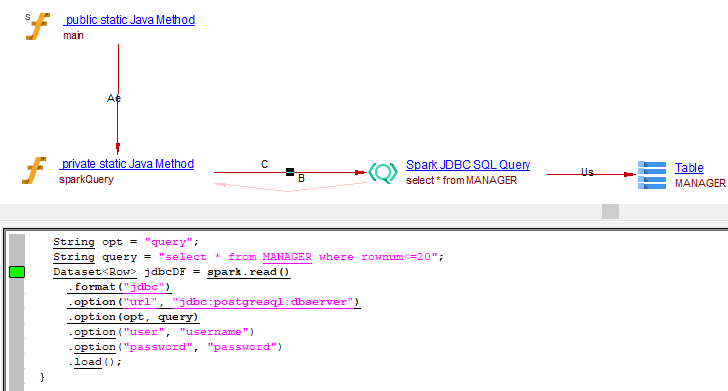
using query
private static void sparkQuery(SparkSession spark) {
String opt = "query";
String query = "select * from MANAGER where rownum<=20";
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option(opt, query)
.option("user", "username")
.option("password", "password")
.load();
}
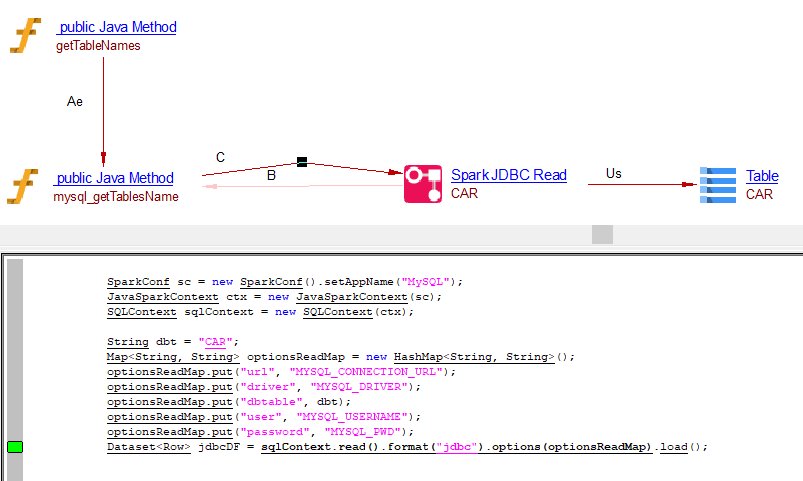
Read operation using Map
public List<String> getTableNames(String JDBC_URI,String JDBC_username,String JDBC_password) {
List<String> TablesList = mysql_getTablesName("URL", "username", "password");
return TablesList;
}
public List<String> mysql_getTablesName(String query, String uri, String username, String password) {
SparkConf sc = new SparkConf().setAppName("MySQL");
JavaSparkContext ctx = new JavaSparkContext(sc);
SQLContext sqlContext = new SQLContext(ctx);
String dbt = "CAR";
Map<String, String> optionsReadMap = new HashMap<String, String>();
optionsReadMap.put("url", "MYSQL_CONNECTION_URL");
optionsReadMap.put("driver", "MYSQL_DRIVER");
optionsReadMap.put("dbtable", dbt);
optionsReadMap.put("user", "MYSQL_USERNAME");
optionsReadMap.put("password", "MYSQL_PWD");
Dataset<Row> jdbcDF = sqlContext.read().format("jdbc").options(optionsReadMap).load();
}
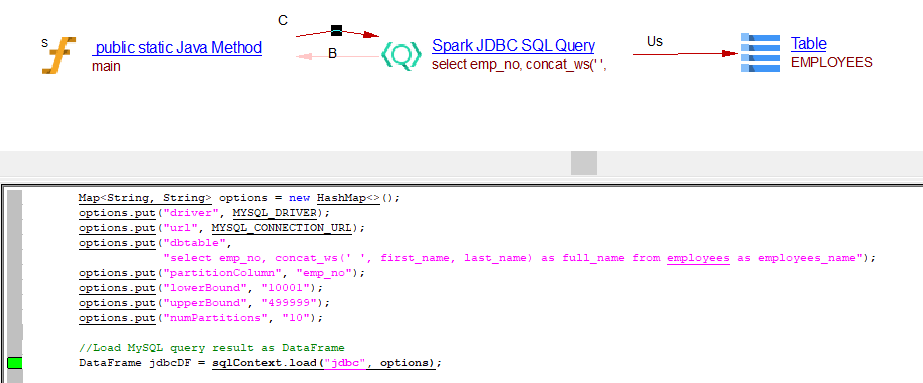
Read operation through SQLContext.load() API using Map
public static void main(String[] args) {
//Data source options
Map<String, String> options = new HashMap<>();
options.put("driver", MYSQL_DRIVER);
options.put("url", MYSQL_CONNECTION_URL);
options.put("dbtable",
"(select emp_no, concat_ws(' ', first_name, last_name) as full_name from employees) as employees_name");
options.put("partitionColumn", "emp_no");
options.put("lowerBound", "10001");
options.put("upperBound", "499999");
options.put("numPartitions", "10");
//Load MySQL query result as DataFrame
DataFrame jdbcDF = sqlContext.load("jdbc", options);
List<Row> employeeFullNameRows = jdbcDF.collectAsList();
for (Row employeeFullNameRow : employeeFullNameRows) {
LOGGER.info(employeeFullNameRow);
}
}
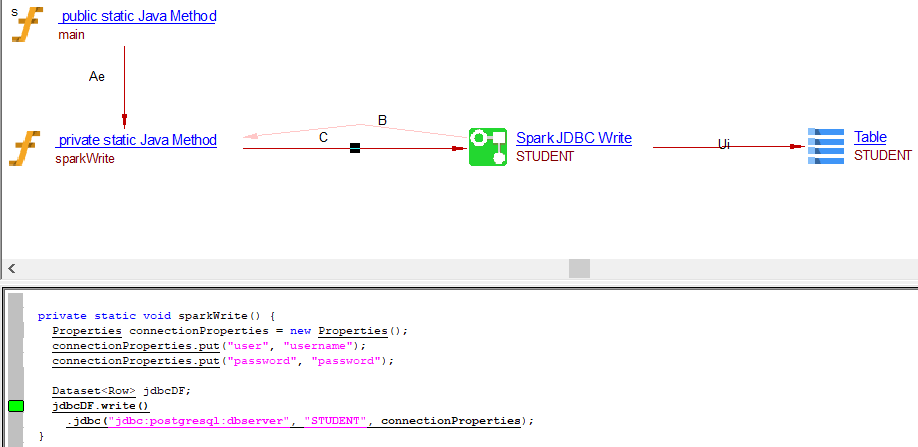
Write Operation
Write operation through .jdbc() API
private static void sparkWrite() {
Properties connectionProperties = new Properties();
connectionProperties.put("user", "username");
connectionProperties.put("password", "password");
Dataset<Row> jdbcDF;
jdbcDF.write()
.jdbc("jdbc:postgresql:dbserver", "STUDENT", connectionProperties);
}
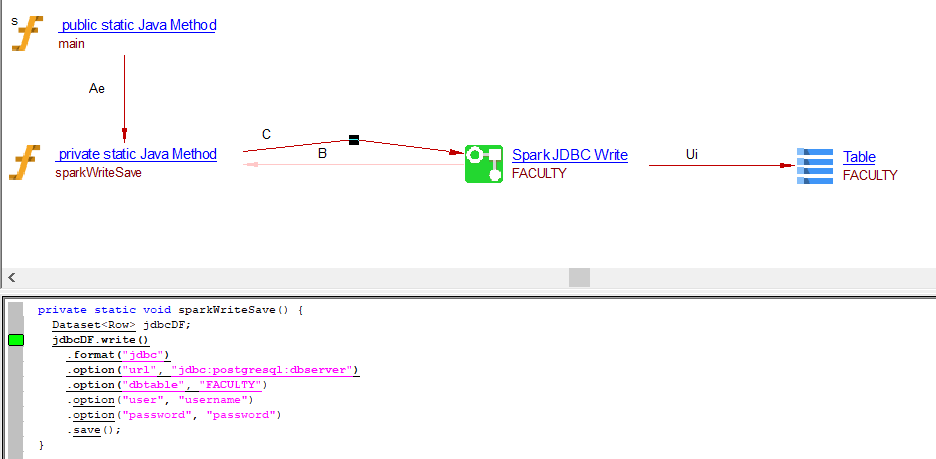
Write operation through .save() API
private static void sparkWriteSave() {
Dataset<Row> jdbcDF;
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "FACULTY")
.option("user", "username")
.option("password", "password")
.save();
}
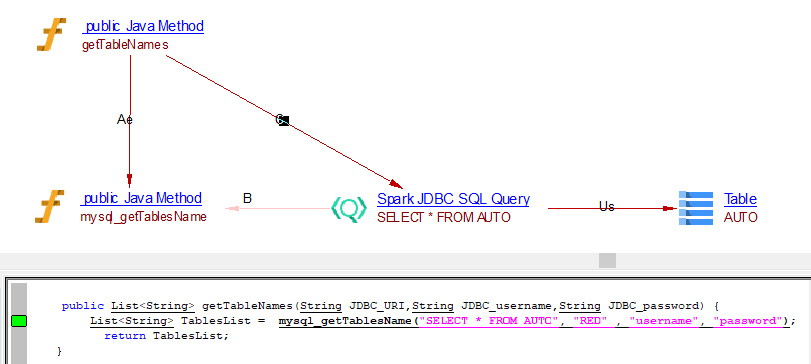
Write operation using Map
public List<String> getTableNames(String JDBC_URI,String JDBC_username,String JDBC_password) {
List<String> TablesList = mysql_getTablesName("SELECT * FROM AUTO", "RED" , "username", "password");
return TablesList;
}
public List<String> mysql_getTablesName(String query, String uri, String username, String password) {
Map<String, String> optionsWriteMap = new HashMap<String, String>();
optionsWriteMap.put("url", "MYSQL_CONNECTION_URL");
optionsWriteMap.put("driver", "MYSQL_DRIVER");
optionsWriteMap.put("dbtable", query);
optionsWriteMap.put("user", "MYSQL_USERNAME");
optionsWriteMap.put("password", "MYSQL_PWD");
Dataset<Row> DF;
DF.write().format("jdbc").options(optionsWriteMap).save();
}
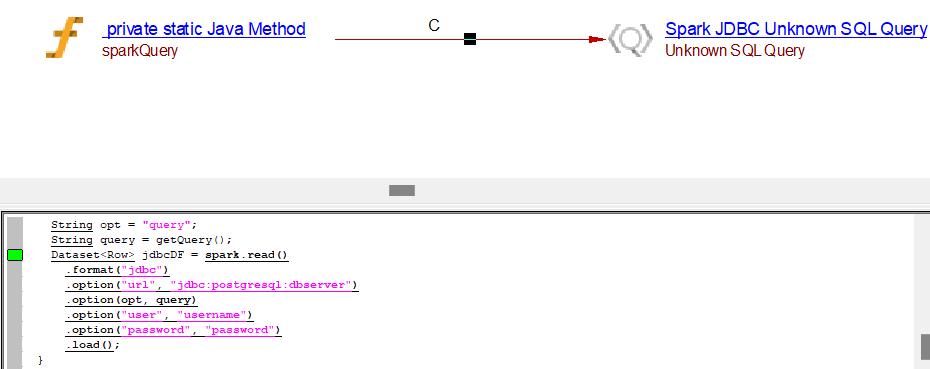
Unknown SQL Query
private static void sparkQuery(SparkSession spark) {
String opt = "query";
String query = getQuery();
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option(opt, query)
.option("user", "username")
.option("password", "password")
.load();
}