Spring Data - 2.1
Extension ID
com.castsoftware.springdata
What’s new?
See Spring Data - 2.1 - Release Notes for more information.
Description
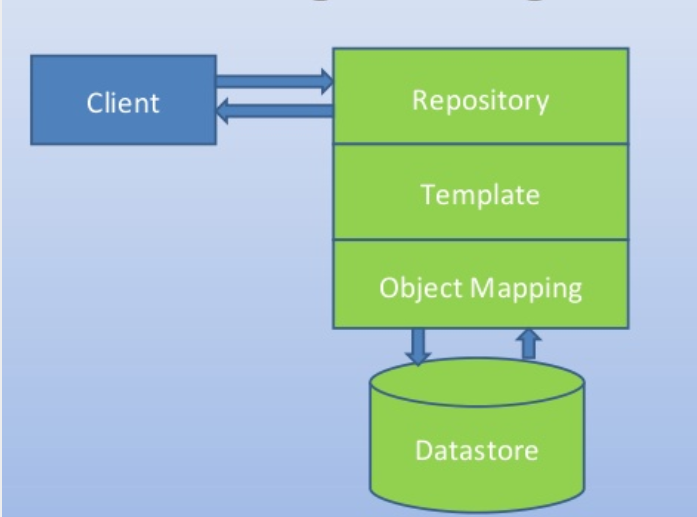
This extension is specifically targeted at the Spring Data and Spring JDBC frameworks and should be used in conjunction with the JEE Analyzer extension. CRUD operations and Named Queries (@NamedQuery and @NamedQueries Annotations) are supported for JPA and JDBC. In addition, this extension provides support for JdbcTemplatewhich is the main Spring JDBC API, which allows access to almost all functionalities of this framework. We focus here on running basic queries and running queries with named parameters.
When client code uses any of these coding mechanisms, the extension will create the links from the calling method to the database table. This helps form the complete transaction.
Technology support
| Library | Version | Supported | Supported Technology |
|---|---|---|---|
| Spring Data JPA | Up to v3.1.x | ✔️ | Java |
| Spring Data JDBC | Up to v3.1.x | ✔️ | Java |
| Spring JDBC | Up to v6.0.x | ✔️ | Java |
| Querydsl JPA Support | From 3.7.x to 5.0.x | ✔️ | Java |
Download and installation instructions
The extension will be automatically downloaded and installed in CAST Console in the following situations:
- Whenever Java source code is delivered and detected.
- Whenever a supported Spring Data JPA or JDBC Framework is delivered and detected.
What results can you expect?
Objects
| Icons | Description |
|---|---|
 |
Spring Data Query |
|
Spring JDBC Query |
 |
Spring Data JPQL Query |
Links
This spring data extension will create the links between objects that are created by the JEE analyzer (the JAVA Methods). For CRUD function calls and queries by inference links to entities handled by com.castsoftware.java.hibernate are created. In the case of database queries, if native queries or JDBC queries are invoked, Spring Data Query objects and respectively Spring JDBC Query objects are created and SQL Analyzer will handle the link to the table. In the case of the JPQL queries the extension creates Spring Data JPQL Query objects. The queries are registered for Java Persistence Framework and are handled by com.castsoftware.java.hibernate extension to create links to entity operations.
The following links are generated for query functions by inference and CRUD function calls:
| Link type | Methods |
|---|---|
| useSelectLink | find..By methods |
| useDeleteLink | delete, delete.., flush methods |
| useUpdateLink | save, save.. methods |
| accessReadLink | read..By, query..By, count..By, get..By, exists, fetch, count, read methods |
Features
Supported annotations
| Annotation Name | Annotation Class |
|---|---|
| @Query | javax.persistence.Query jakarta.persistence.Query org.springframework.data.jpa.repository.Query org.springframework.data.jdbc.repository.query.Query |
| @NamedQuery | javax.persistence.NamedQuery jakarta.persistence.NamedQuery |
| @NamedQueries | javax.persistence.NamedQueries jakarta.persistence.NamedQueries |
| @NamedNativeQuery | javax.persistence.NamedNativeQuery jakarta.persistence.NamedNativeQuery |
| @NamedNativeQueries | javax.persistence.NamedNativeQueries jakarta.persistence.NamedNativeQueries |
| @Procedure | org.springframework.data.jpa.repository.query.Procedure |
Managing CRUD method calls
Spring Data Repository abstraction is used to significantly reduce the amount of boilerplate code required to implement data access layers for various persistence stores. A number of CRUD methods are provided to improve data access. The supported CRUD APIs are mentioned in the table below.
| package | Repository Class | CRUD Functions |
|---|---|---|
| org.springframework.data.jpa.repository | JpaRepository | deleteInBatch, deleteAllInBatch, findAll, flush, saveAndFlush, saveAllAndFlush |
| JpaSpecificationExecutor | count, delete, exists, findAll, findBy, findOne | |
| org.springframework.data.repository | CrudRepository | count, delete, deleteAll, deleteAllById, deleteById, existsById, findAll, findAllById, findById, save,saveAll |
| ListCrudRepository | findAll, findAllById, saveAll | |
| ListPagingAndSortingRepository | findAll | |
| PagingAndSortingRepository | findAll | |
| org.springframework.data.repository.query | QueryByExampleExecutor | count, exists, findAll, findBy, findOne |
| ListQueryByExampleExecutor | findAll | |
| query.ReactiveQueryByExampleExecutor | count, exists, findAll, findBy, findOne | |
| org.springframework.data.querydsl | QuerydslPredicateExecutor | count, exists, findAll, findBy, findOne |
| ListQuerydslPredicateExecutor | findAll | |
| ReactiveQuerydslPredicateExecutor | count, exists,findAll,findBy,findOne | |
| org.springframework.data.repository.reactive | ReactiveCrudRepository | count, delete, deleteAll, deleteAllById, deleteById, existsById, findAll, findAllById, findById, save, saveAll |
| ReactiveSortingRepository | findAll | |
| RxJava3CrudRepository | count, delete, deleteAll, deleteAllById, deleteById, existsById, findAll, findAllById, findById, save, saveAll | |
| RxJava3SortingRepository | findAll |
CRUD examples
package com.cloudfoundry.tothought.repositories;
import org.springframework.data.jpa.repository.JpaRepository;
import com.cloudfoundry.tothought.entities.Post;
public interface PostRepository extends JpaRepository<Post, Integer> {
}
@Autowired
PostRepository repository;
@Transactional
public void check(Post post)
{
repository.delete(post);
}
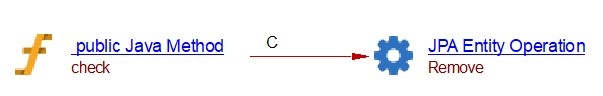
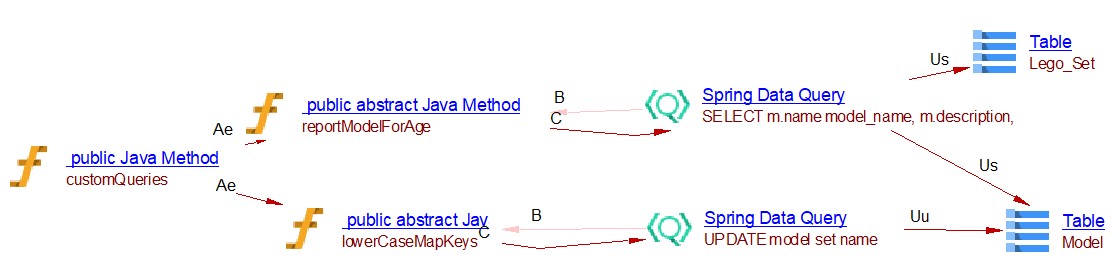
Custom Repository methods with @Query annotation
In Spring Data, we write queries in plain SQL. Custom methods are decorated with the @Query annotation and inside we have the SQL query.
import org.springframework.data.jdbc.repository.query.Query;
interface LegoSetRepository extends CrudRepository<LegoSet, Integer> {
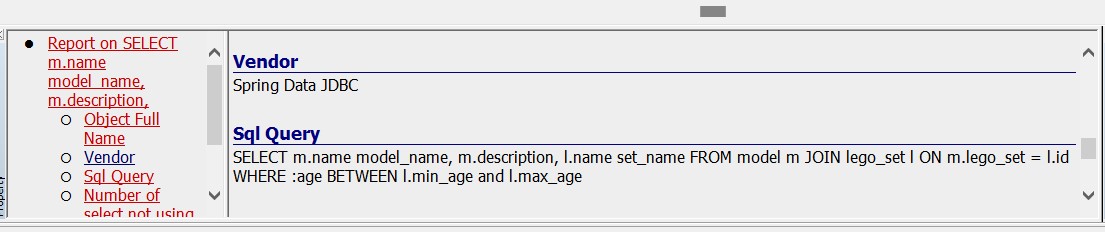
@Query("SELECT m.name model_name, m.description, l.name set_name" +
" FROM model m" +
" JOIN lego_set l" +
" ON m.lego_set = l.id" +
" WHERE :age BETWEEN l.min_age and l.max_age")
List<ModelReport> reportModelForAge(@Param("age") int age);
@Modifying
@Query("UPDATE model set name = lower(name) WHERE name <> lower(name)")
int lowerCaseMapKeys();
}
public void customQueries() {
List<ModelReport> report = repository.reportModelForAge(6);
}
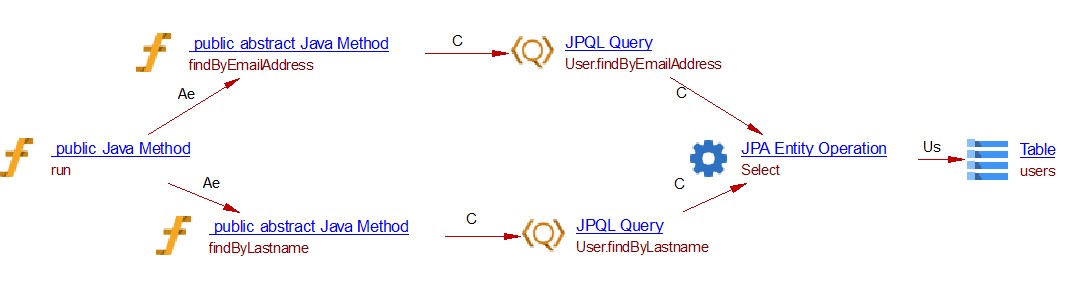
Named Queries
Using JPA NamedQueries
The @NamedQuery annotations can be used individually or can coexist in the class definition for an entity. The annotations define the name of the query, as well as the query text. In a real application, you will probably need multiple named queries defined on an entity class. For this, you will need to place multiple @NamedQuery annotations inside a @NamedQueries annotation.
Example @NamedQueries code:
@Entity
@Table(name = "users")
@NamedQuery(name = "User.findByEmailAddress", query = "select u from User u where u.emailAddress = ?1")
@NamedQueries(value = {
@NamedQuery(name = "User.findByLastname", query = "select u from User u where u.lastname = ?1") })
public class User {
...
}
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
...
/
* UserRepository demonstrates the method name query generation.
*/
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
User findByEmailAddress(String emailAddress);
List<User> findByLastname(String lastname);
}
@Override
public void run(String... args) throws Exception {
...
User user2 = userRepository.findByEmailAddress("ramesh24@gmail.com");
List<User> user3 = userRepository.findByLastname("Fadatare");
}
The code listed above will produce the following links and objects when the Spring Data extension is installed:
Using JPA NamedNativeQueries
import javax.persistence.*;
@Entity
@Table(name = "order_table")
@NamedNativeQuery(name = "Address.findAllNameIds", query = "SELECT order_table.id as order_id, add.address_first_name as first_name, add.address_last_name as last_name "
+ "FROM order_table , address as add " + "WHERE order_table.id IN ?1 "
+ "AND order_table.delivery_address_id = add.id ", resultSetMapping = "deliveryNamePerOrder")
public class Address {
...
}
import org.springframework.data.jpa.repository.JpaRepository;
public interface AddressRepository extends JpaRepository<Address, UUID> {
List<DeliveryNameForOrderDto> findAllNameIds(List<UUID> ordersList);
}

Using JPA NamedQueries via XML
NamedQuery works with annotations as well as with XML files. The application’s web.xml file contains the param-value which indicates the XML file that contains the named query. Using the Spring Data extension, proper links can be created from the methods which call these queries to the data base table.
web.xml
<web-app id="WebApp_ID" version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Spring-data Application</display-name>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/spring-servlet.xml,/WEB-INF/orm.xml
</param-value>
</context-param>
orm.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="1.0">
<!-- <persistence-unit name="myUnit" transaction-type="RESOURCE_LOCAL">
<mapping-file>META-INF/orm.xml</mapping-file>
<exclude-unlisted-classes/>
</persistence-unit> -->
<!-- Named Query using XML Configuration -->
<named-query name="Owner.findByEmailAddress">
<query>select u from Owner u where u.emailAddress = ?1</query>
</named-query>
</persistence>
@Entity
@Table(name = "Owners")
public class Owner {
...
}
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
...
/
* OwnerRepository demonstrates the method name query generation.
*/
@Repository
public interface OwnerRepository extends JpaRepository<Owner, Long> {
Owner findByEmailAddress(String emailAddress);
}
The code listed above will produce the following links and objects when the Spring Data extension is installed. A link will be created from the method namedQueryCall to the JPQL Query object:

Creating query by inference in Spring Data JPA
The query builder mechanism of Spring Data is useful for building
queries over entities of the repository. The mechanism is to create the
query for patterns such as find..By, read..By, query..By,
count..By, and get..By. Spring Data parses this string as it may
contain further expressions, such as a Distinct to set a distinct
flag on the query to be created. However, the first By acts as
delimiter to indicate the start of the actual criteria. In the Spring
Data extension, the transaction link can be drawn from these methods to
the database table.
import java.io.Serializable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.NoRepositoryBean;
@NoRepositoryBean
public interface BaseRepository<T, ID extends Serializable> extends JpaRepository<T, ID>, JpaSpecificationExecutor<T> {
}
import java.util.List;
import org.springframework.data.repository.query.Param;
public interface SettingRepository extends BaseRepository<Setting, Long> {
List<Setting> findByKey(@Param("key") String key);
}
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.EnumType;
import javax.persistence.Enumerated;
import javax.persistence.Table;
@Entity
@Table(name = "TABLE_SETTING")
public class Setting {
...
}
public getMessage(String key) {
List<Setting> settings = settingRepository.findByKey(key);
...
}
The code listed above will produce the following links and objects when the Spring Data extension is installed:

Creating query by inference in Spring Data JPA with @Query annotation
@Entity
@Table(name = "users")
public class User {
...
}
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress(String emailAddress);
@Query("select u from User u where u.firstname like %?1")
List<User> findByFirstnameEndsWith(String firstname);
}
@Override
public void run(String... args) throws Exception {
...
User user = userRepository.findByEmailAddress("john@gmail.com");
System.out.println(user.toString());
List<User> user3 = userRepository.findByFirstnameEndsWith("John");
...
}
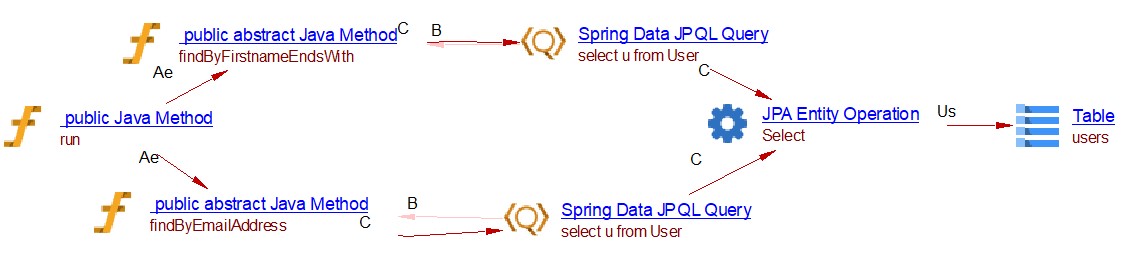
Spring Data JPA @Procedure annotation support
In the case of @Procedure annotation, the spring data extension creates Spring Data Query objects which are linked to the Java method that declares it in the Repository interface. SQL analyser is in charge of creating the links to the tables. One exception exits when the @Procedure annotation contains the parameter name “name” which indicates a Named Store Procedure Query that must be declared in the associated Entity class. The spring data extension collects the JPA SQL Query, created by java.hibernate extension, as part of the support of Named Store Procedure Query and create the link from the Java method annotated by @Procedure to the JPA SQL Query instead of the Spring Data Query.
With the following Entity Class:
@Entity
@Table(name = "Subscribers")
@NamedStoredProcedureQuery(
name = "Subscriber.getSubscriberByUsernameNamedProcedure",
procedureName = "GET_SUBSCRIBER_BY_USERNAME5",
parameters = {
@StoredProcedureParameter(mode = ParameterMode.IN, type = String.class, name = "username")
}
)
public class Subscriber {
...
}
The Repository Interface:
public interface SubscriberRepository extends JpaRepository<Subscriber, Long> {
// Procedure without specifying a procedure name
@Procedure
String GET_SUBSCRIBER_BY_USERNAME(@Param("username") String username);
// Procedure with a custom procedure name
@Procedure("GET_SUBSCRIBER_BY_USERNAME2")
String getSubscriberByUsernameProcedure(@Param("username") String username);
// Procedure with the procedureName attribute
@Procedure(procedureName = "GET_SUBSCRIBER_BY_USERNAME3")
String getSubscriberByUsernameProcedure2(@Param("username") String username);
// Procedure with the value attribute
@Procedure(value = "GET_SUBSCRIBER_BY_USERNAME4")
String getSubscriberByUsernameProcedure3(@Param("username") String username);
// Procedure with the name attribute referencing a named stored procedure
@Procedure(name = "Subscriber.getSubscriberByUsernameNamedProcedure")
String getSubscriberByUsernameNamedProcedure(@Param("username") String username);
}
The associated result in Enlighten are:

Native queries support
In the case of native queries, the spring data extension creates Spring Data Query objects which are linked to the Java methods. SQL analyzer is in charge of creating the links to the tables. We can detect that a query is native by the parameter nativeQuery = true inside. if nativeQuery = false or is absent then the query is a JPQL query.
Creating query by inference in Spring Data JPA with @Query annotation : support of nativeQuery parameter
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "select u from Users u where u.emailAddress = ?1", nativeQuery = true)
User findByEmailAddress(String emailAddress);
}
@Override
public void run(String... args) throws Exception {
...
User user = userRepository.findByEmailAddress("john@gmail.com");
System.out.println(user.toString());
...
}


Handling Query Dsl in Spring Data JPA
| package | QueryDsl classes | Supported APIs |
|---|---|---|
| com.querydsl.jpa.impl | JPAQueryFactory | from, selectFrom |
| JPAQuery | from | |
| JPADeleteClause | execute | |
| JPAInsertClause | execute | |
| JPAUpdateClause | execute | |
| com.querydsl.jpa | JPAQueryBase | from |
| com.mysema.query.jpa.impl | JPAQuery | from |
| JPAQueryFactory | from | |
| JPAUpdateClause | execute | |
| JPADeleteClause | execute | |
| com.mysema.query.jpa | JPAQueryBase | from |
Querydsl is a framework which enables the construction of statically typed SQL-like queries, instead of writing queries as inline strings.Querydsl for JPA/Hibernate is an alternative to both JPQL and JPA 2 Criteria queries. It combines the dynamic nature of Criteria queries with the expressiveness of JPQL and all that in a fully typesafe manner.
To include Querydsl in the project, dependencies should be present in the project.
<properties>
<querydsl.version>4.1.3</querydsl.version>
</properties>
<dependencies>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>${querydsl.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>
</dependencies>
The querydsl-apt dependency is an annotation processing tool. It allows processing of annotations in source files before they move on to the compilation stage. This tool generates the so called Q-types — classes that directly relate to the entity classes of your application, but are prefixed with letter Q. For instance, if you have a User class marked with the @Entity annotation in your application, then the generated Q-type will reside in a QUser.java source file.
Example: Product.java
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
@Entity
@Table(name="PRODUCT")
public class Product {
@Id
private Long id;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public Category getCategory() {
return category;
}
public void setCategory(Category category) {
this.category = category;
}
private String name;
private double price;
@ManyToOne
private Category category;
}
DemoService.java
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import static com.mysema.demo.QProduct.product;
import com.querydsl.jpa.impl.JPAQuery;
public class DemoService {
public List<Product> findProductsByNameAndCategoryId(String name, Long categoryId){
QProduct myQproduct;
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("persistence");
EntityManager entityManager = entityManagerFactory.createEntityManager();
QCategory cat = QCategory.category;
JPAQueryFactory qry = new JPAQueryFactory(entityManager);
qry.from(myQproduct);
if(name != null){
qry.select(myQproduct.name.like(name));
}
if(categoryId != null){
qry.select(myQproduct.category.catId.eq(categoryId));
}
return qry.fetch();
}
private JPAQuery createQuery(QProduct product,JPAQuery qr) {
return (JPAQuery) qr.from(product);
}
}
The following link is created with above code when the Spring Data
extension is used:

Support for Spring Boot Starter
Spring-boot-starter-data-jpa POM provides a quick way to get started. It provides the following key dependencies
- Hibernate: One of the most popular JPA implementations.
- Spring Data JPA: Makes it easy to implement JPA-based repositories.
The Spring Boot application invokes the application which uses the Spring Data JPA. For example, the source code below shows how the Spring Boot Starter invokes the Spring Data JPA application:
Application.java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.data.web.config.EnableSpringDataWebSupport;
import com.onlinetutorialspoint.entity.Person;
import com.onlinetutorialspoint.repository.PersonRepository;
import com.onlinetutorialspoint.service.PersonService;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
@Autowired
PersonService personService;
@Bean
public CommandLineRunner run(PersonRepository repository) {
return (args) -> {
Person person = new Person();
person.setName("Chandra Shekhar Goka");
person.setCity("Hyderabad");
Person p = savePersonDetails(person);
System.out.println("Person Id : "+p.getId() +" Person Name : "+p.getName());
};
}
public Person savePersonDetails(Person p){
return personService.savePerson(p);
}
public Person getPerson(Person person){
return personService.getPerson(person.getId());
}
}
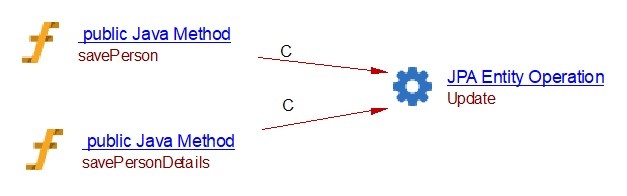
PersonService.java
@Service
@Transactional
public class PersonService {
@Autowired
PersonRepository personRepo;
public void savePersonDetails(PersonDTO personDto) {
try {
Person person = new Person();
person.setCity(personDto.getpCity());
person.setName(personDto.getpName());
person.setId(personDto.getPid());
personRepo.save(person);
} catch (Exception e) {
e.printStackTrace();
}
}
public Person savePerson(Person person) {
return personRepo.save(person);
}
}
Person.java
@Entity
@Table(name = "person")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Column(name="pcity")
private String city;
public Person() {
super();
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Person [pid=" + id + ", pName=" + name + ", pCity=" + city
+ "]";
}
}
The code above will produce the following objects and links:
Support for Spring JDBC
| packages | Spring JDBC Classes | Supported APIs |
|---|---|---|
| org.springframework.jdbc.core.simple | SimpleJdbcTemplate | batchUpdate, query, queryForInt, queryForList, queryForLong, queryForMap, queryForObject, update |
| SimpleJdbcInsert | execute, executeAndReturnKey, executeAndReturnKeyHolder | |
| SimpleJdbcCall | execute, executeFunction, executeObject | |
| SimpleJdbcInsertOperations | execute, executeAndReturnKey, executeAndReturnKeyHolder | |
| SimpleJdbcCallOperations | execute, executeFunction, executeObject | |
| AbstractJdbcInsert | doExecute, doExecuteAndReturnKey, doExecuteAndReturnKeyHolder, doExecuteBatch | |
| AbstractJdbcCall | doExecute | |
| org.springframework.jdbc.core | JdbcTemplate | batchUpdate, execute, query, queryForList, queryForMap, queryForObject, queryForRowSet, queryForStream, update |
| JdbcOperations | batchUpdate, execute, query, queryForList, queryForMap, queryForObject, queryForRowSet, queryForStream, update | |
| org.springframework.jdbc.core.namedparam | NamedParameterJdbcTemplate | batchUpdate, query, queryForInt, queryForLong, queryForList, queryForMap, queryForObject, queryForRowSet, queryForStream, update |
To populate the databases, Spring JDBC JdbcTemplates and NamedParameterJdbcTemplate APIs are used. This extension supports them also and creates Spring JDBC Query objects.
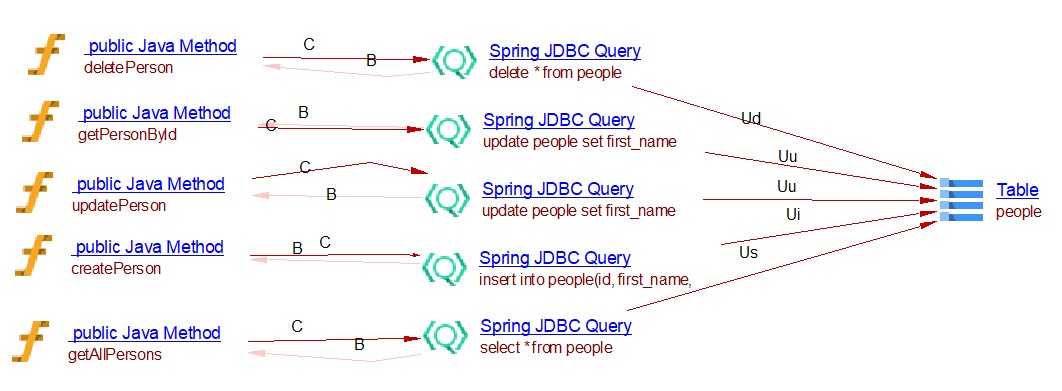
JdbcTemplate queries support
public class PersonDAOImpl implements PersonDAO {
JdbcTemplate jdbcTemplate;
private static final String SQL_FIND_PERSON = "select * from people where id = ?";
private static final String SQL_DELETE_PERSON = "delete from people where id = ?";
private static final String SQL_UPDATE_PERSON = "update people set first_name = ?, last_name = ?, age = ? where id = ?";
private static final String SQL_GET_ALL = "select * from people";
private static final String SQL_INSERT_PERSON = "insert into people(id, first_name, last_name, age) values(?,?,?,?)";
@Autowired
public PersonDAOImpl(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
public Person getPersonById(Long id) {
return jdbcTemplate.queryForObject(SQL_FIND_PERSON, new Object[]{id}, new PersonMapper());
}
public List<Person> getAllPersons() {
return jdbcTemplate.query(SQL_GET_ALL, new PersonMapper());
}
public boolean deletePerson(Person person) {
return jdbcTemplate.update(SQL_DELETE_PERSON, person.getId()) > 0;
}
public boolean updatePerson(Person person) {
return jdbcTemplate.update(SQL_UPDATE_PERSON, person.getFirstName(), person.getLastName(), person.getAge(),
person.getId()) > 0;
}
public boolean createPerson(Person person) {
return jdbcTemplate.update(SQL_INSERT_PERSON, person.getId(), person.getFirstName(), person.getLastName(),
person.getAge()) > 0;
}
}

NamedParameterJdbcTemplate queries support
public Map<Long, UserDetail> getUserDetails(String subQuery, Map<String, Object> parameterValues) {
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
MapSqlParameterSource parameters = new MapSqlParameterSource(parameterValues);
String sqlQuery = "select usr.userid from users";
userDetails = namedParameterJdbcTemplate.query(sqlQuery, parameters);
}

SimpleJdbcInsert and SimpleJdbcInsertOperations support
| Spring JDBC Class | Supported APIs |
|---|---|
| org.springframework.jdbc.core.simple.SimpleJdbcInsert | execute, executeBatch, executeAndReturnKey, executeAndReturnKeyHolder |
| org.springframework.jdbc.core.simple.SimpleJdbcInsertOperations | execute, executeBatch, executeAndReturnKey, executeAndReturnKeyHolder |
This API provides insert capabilities into a table. The methods calling the supported APIs will be linked to tables. The API withTableName() helps identifying the table.
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.simple.SimpleJdbcCall;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Repository;
@Repository
public class Main
{
private JdbcTemplate jdbcTemplate;
private SimpleJdbcInsert simpleJdbcInsert;
private SimpleJdbcCall simpleJdbcCall;
@Autowired
public void setDataSource(DataSource dataSource)
{
this.jdbcTemplate = new JdbcTemplate(dataSource);
simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate).withTableName("JdbcTask").usingGeneratedKeyColumns("id");
this.simpleJdbcCall = new SimpleJdbcCall(jdbcTemplate);
Map<String, Object> args = new HashMap<String, Object>(2);
args.put("personid", task.getPersonId());
simpleJdbcInsert.execute(args);
}
}

SimpleJdbcCall and SimpleJdbcCallOperations support
This API represents a call to a stored procedure or a stored function. In this extension we handle the stored procedures. The methods calling execute() will be linked to procedures. The withProcedureName() call helps us identify the procedure.
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.jdbc.core.simple.SimpleJdbcCall;
class Main
{
private JdbcTemplate jdbcTemplateObject;
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
this.jdbcTemplateObject = new JdbcTemplate(dataSource);
}
public Student getStudent(Integer id) {
SimpleJdbcCall jdbcCall = new SimpleJdbcCall(dataSource).withProcedureName("getRecord");
SqlParameterSource in = new MapSqlParameterSource().addValue("in_id", id);
Map<String, Object> out = jdbcCall.execute(in);
}
}
Table declaration:
CREATE TABLE Student(
ID INT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
AGE INT NOT NULL,
PRIMARY KEY (ID)
);
Procedure declaration:
DELIMITER $$
DROP PROCEDURE IF EXISTS `TEST`.`getRecord` $$
CREATE PROCEDURE `TEST`.`getRecord` (
IN in_id INTEGER,
OUT out_name VARCHAR(20),
OUT out_age INTEGER)
BEGIN
SELECT name, age
INTO out_name, out_age
FROM Student where id = in_id;
END $$
DELIMITER ;

Function Point, Quality and Sizing support
This extension provides the following support:
| Function Points (transactions) |
Quality and Sizing |
|---|---|
| ✔️ | ❌ |
Compatibility
| CAST Imaging Core | Supported |
|---|---|
| 8.3.x | ✔️ |
Dependencies with other extensions
Some CAST extensions require the presence of other CAST extensions in order to function correctly. The SPRING-DATA extension requires that the following other CAST extensions are also installed:
- com.castsoftware.internal.platform (internal technical extension).
- com.castsoftware.java.hibernate
Limitations
In QueryDsl framework, the generated Q-type classes must be present in the source files. The code analysis is based on their presence. If it is not the case, no link will be created between calling methods and tables.