Analysis configuration
CAST Console
Starting 3.6.0-funcrel, analysis configuration settings are available after an onboarding/fast-scan and before the initial analysis. For all other releases, analysis configuration options are only exposed after an initial analysis.
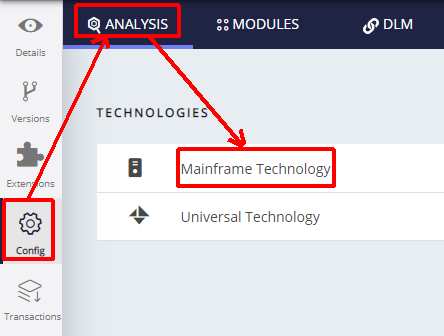
Technology settings are organized as follows:
- Settings specific to the technology for the entire Application
- List of Analysis Units (a set of source code files to analyze)
created for the Application
- Settings specific to each Analysis Unit (typically the settings are the same as at Application level) that allow you to make fine-grained configuration changes.
You should check that settings are as required and that at least one Analysis Unit exists for the specific technology.
| Working folder | Available in AIP Console ≥ 1.25 This option allows you to choose list of folders that will be searched in order to resolve Copybook links, Cobol program links, catalogued procedure links and include file links. Any Copybooks identified will not be analyzed, but will instead be included in the code of any programs that call them. |
||||
|---|---|---|---|---|---|
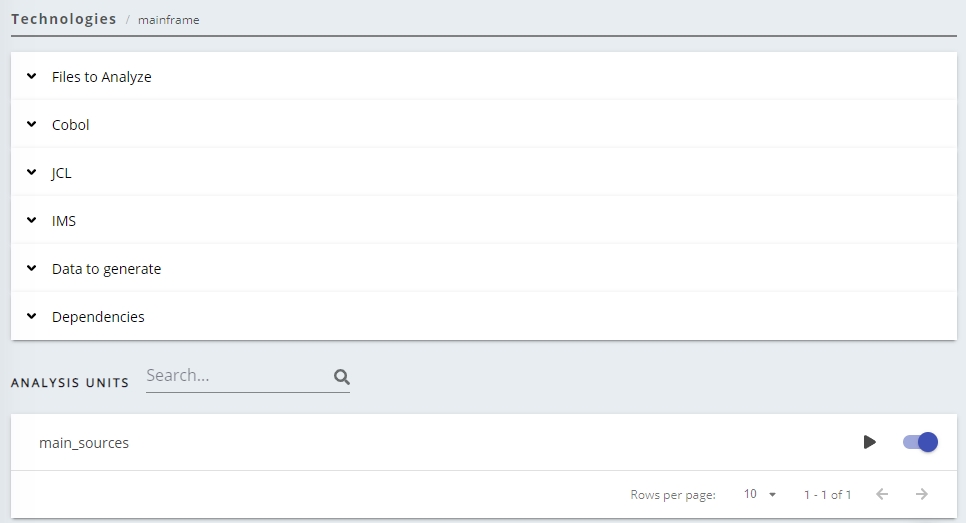
| Files to Analyze | This section displays a list of the file extensions for Cobol, CICS, IMS and JCL that are included in the current file filter for your source code analysis. Only files that match these file extensions will be included in the analysis. | ||||
Cobol
|
Platform: IBM z/OS This option specifies that the code runs on the Mainframe environment and thus the analyzer will handle the code accordingly. Selecting this option means that:
If you want to analyze code that runs on a different platform, do disable this option. |
||||
Source Code in Free-Form Format If this option is checked, then it will be considered that the Cobol source code is not 80-columns formatted. If this option is not checked, then it will be considered that the Cobol code respects the standard format. |
|||||
Source code can be placed beyond column 72 By default this option is unselected, however, when selected, the analyzer will assume that all information included beyond column 72 is code and process it when the analysis is run. When unselected, information placed beyond column 72 is ignored. |
|||||
Exclude copybook files This option is set to true (active) by default. When set to true:
When set to false:
|
|||||
Save Sections and Paragraphs Selecting this option will force the analyzer to take into account paragraphs and sections in the selected source code and save them in the Analysis Service. If you are working with a particularly large project, deactivating this option can improve performance during the analysis process. |
|||||
| JCL | Advanced JCL file configuration path Enables you to define an AdvancedJCL.xml file (to parameterize your Mainframe JCl analysis) for the current Application. See Parameterization for JCL - AdvancedJCL.xml below for more information about this option. |
||||
| IMS | Column for indicator area This option provides the means to specify the column used for comment flags ('*'). In standard format, the indicator area is located at column 1 (one). |
||||
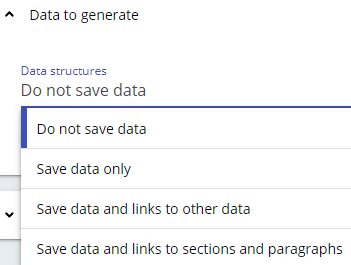
| Data to generate | Data Structures
Do not save data Selecting this option (default position) will cause variable data structure (such as: data objects from their definition in the data division and literal objects from their usage in data initialization and manipulations) to be ignored during the analysis. Save data only Selecting this option will cause variable data structure (such as: data objects from their definition in the data division and literal objects from their usage in data initialization and manipulations) to be saved to the CAST Analysis Service. No corresponding links will be created in the CAST Analysis Service. To create links involving these objects, please select either of the Save data and links... options below. Selecting this option will negatively affect performance during the analysis process - i.e. the analysis will take longer to complete. The larger the analysis (i.e. in terms of volume of source code), the longer the analysis will take. Save data and links to other data Selecting this option will cause variable data structure (such as: data objects from their definition in the data division and literal objects from their usage in data initialization and manipulations) to be saved to the CAST Analysis Service. In addition, links from data/literals to data will be created. Selecting this option will negatively affect performance during the analysis process - i.e. the analysis will take longer to complete. The larger the analysis (i.e. in terms of volume of source code), the longer the analysis will take. Save data and links to sections and paragraphs Selecting this option will cause variable data structure (such as: data objects from their definition in the data division and literal objects from their usage in data initialization and manipulations) to be saved to the CAST Analysis Service. In addition, data access links from procedure division objects to data/literals will be created. Selecting this option will negatively affect performance during the analysis process - i.e. the analysis will take longer to complete. The larger the analysis (i.e. in terms of volume of source code), the longer the analysis will take. Save data and links to sections and paragraphs and to other data Available when using CAST AIP Core ≥ 8.3.58, com.castsoftware.mainframe ≥ 1.4.0 and CAST Console ≥ 2.11.7. This option is a combination of the Save data and links to other data and Save data and links to sections and paragraphs. Radio options
These options are only visible:
Save only Referenced Data Enabling this option (default position) will cause the Cobol data in copybooks within a Cobol program to be saved if it is referenced (used) by other objects. If disabled, all Cobol data in copybooks within a Cobol program is saved regardless of whether it is referenced or not. Note that starting v. 1.6, this option also saves all Cobol Data in parentship chain of referenced Cobol Data. Save Cobol literal Enabling this option will cause Cobol literal objects to be saved. If disabled (default), no Cobol literal objects will be saved. Save Cobol Conditional test Enabling this option will cause Cobol Conditional test objects to be saved. If disabled (default), no Cobol Conditional test objects will be saved. Save data found in copy books Enabling this option will force ALL data structures found in copybooks to be saved. If disabled (default), no data structures will be saved. |
||||
| Dependencies | Dependencies are configured at Application level for each technology and are configured between individual Analysis Units/groups of Analysis Units (dependencies between technologies are not available as is the case in the CAST Management Studio). You can find out more detailed information about how to ensure dependencies are set up correctly, in Validate dependency configuration. | ||||
| Analysis Units | Lists all Analysis Units created. You can configure the same technology settings at Analysis Unit level if required - click the Analysis Unit to view it's technology settings (by default they match the default settings application wide technology settings):
|

CAST Management Studio
Introduction to analysis configuration options
The CAST Management Studio has three levels at which analysis configuration options can be set:
| Technology |
|
| Application |
|
| Analysis Unit |
|
Some settings at Application and Analysis Unit level have a “Reset” option - using this will reset the option to the value set at the parent level:

Auto-configuration validation
Technology / Application level
Using the Technology level or Application level options, validate the settings for Mainframe packages. Make any update as required. These settings apply to the Technology or Application as a whole (i.e. all Analysis Units):
Click to enlarge
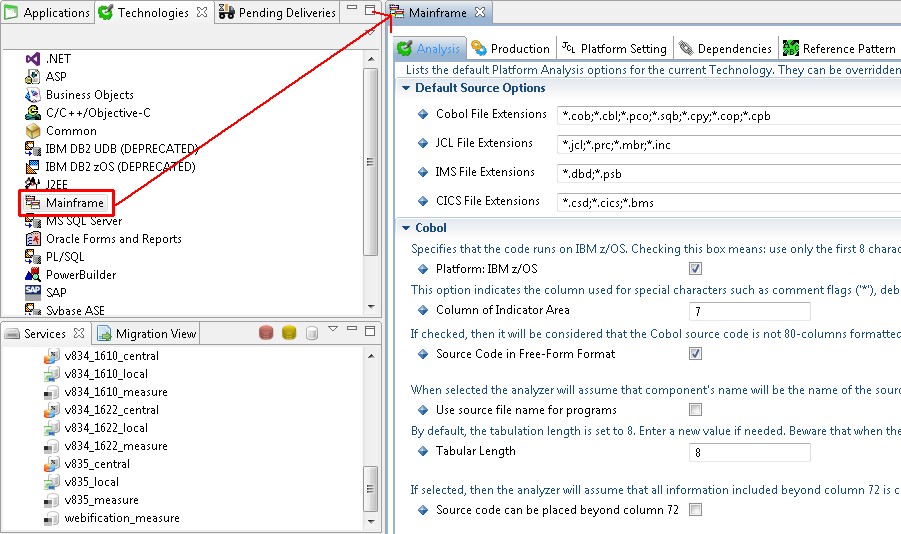
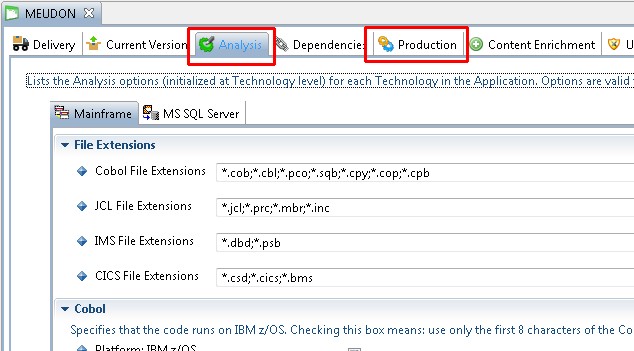
Analysis Unit level
To inspect the auto-generated analysis configuration, you should review the settings in each Analysis Unit - they can be accessed through the Application editor:
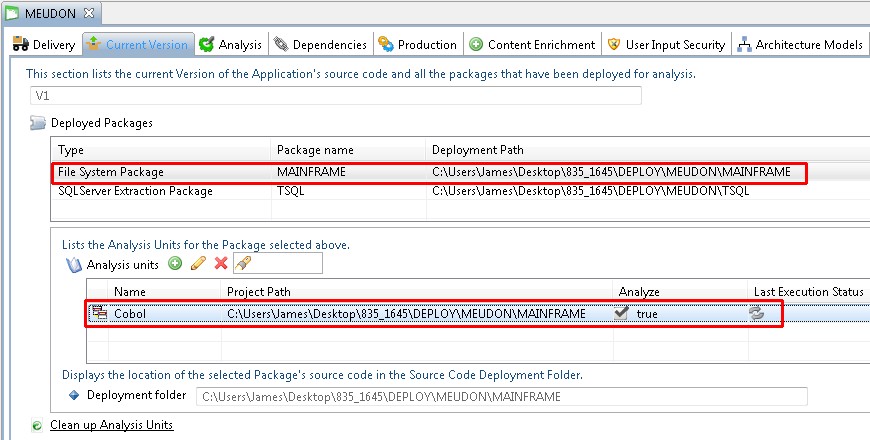
Validate and configure Source Settings at Analysis Unit level
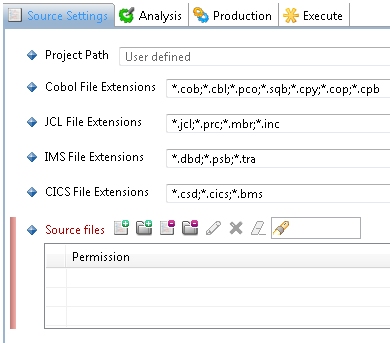
Source files - exclude folders that only contain copybooks
In general, copybooks are stored in libraries and it is very difficult for Delivery Managers to sort them so that only those used in the application are delivered for analysis. As a result, in most situations, all copybooks tend to be delivered for analysis. CAST therefore highly recommends that you use the Source files section in the Source Settings tab to exclude (from the Analysis Unit) ALL folders that ONLY contain copybooks. This avoids the need to analyze all the copybooks, i.e. even those that are not used by the programs. This exclusion reduces the time required to perform the analysis and reduces the amount of source code stored in the various CAST schemas. Only those copybooks that are actually used by programs will actually be analayzed.
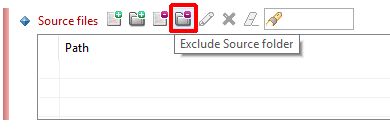
For example, if in the delivered source code there is a folder called “Copy” that only contains copybooks, and folder called “DB2” that only contains copybooks generated by DB2 to map, in COBOL, the table columns (known as DCLGEN), then you would need to use the Exclude Source folder option to exclude both the “Copy” and the “DB2” folders.
You will then need to create corresponding Working Folder entries for all the folders you have excluded here (see the section below about doing this).
Validate and configure Analysis settings at Analysis Unit level
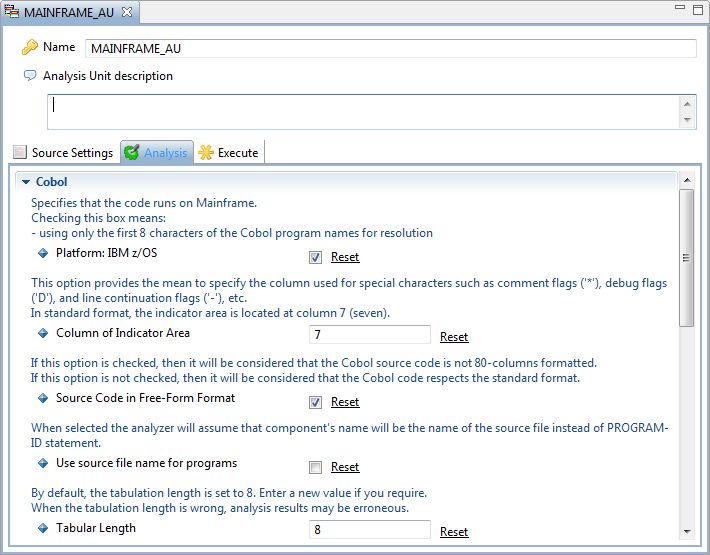
Working Folders
If you have excluded (from an Analysis Unit) folders that ONLY contain copybooks, then CAST highly recommends that you now add Working Folder items to the Analysis Unit that exactly match the folders you have excluded (as explained above).
For example, if in the delivered source code there is a folder called “Copy” that only contains copybooks, and folder called “DB2” that only contains copybooks generated by DB2 to map, in COBOL, the table columns (known as DCLGEN), and these have been excluded from the Analysis Unit, you now need to add two Working Folder items that match the paths of the Copy and DB2 folders:
Advanced configuration (Inference Engine)
If you experience performance, call resolution, or quality rule computation issues, various technical settings related to the Inference Engine can be used. The Inference Engine is heavily used by the Mainframe Analyzer for COBOL to carry out several tasks:
- Building of the paragraph call graphs through the different types of calls allowed by the Cobol language (GO TO, PERFORM, fall through logic)
- Resolving dynamic calls executed through variables
- Computing intermediary results used by some Quality Rules
These settings can be changed in very specific situations for which default parameter values are not sufficient. This can occur when programs to be analyzed are complex. Here, “complex programs” does not necessary mean “large programs” with a high number of lines of code. Instead, it means programs implementing a large control flow graph involving a high number of paragraphs. In this case, results can be partial and it is possible to force the analyzer to generate better results by changing some technical settings. Nevertheless, it is important to keep in mind that the more we force the analyzer to provide accurate results the more the performance decreases.
The Inference Engine default settings are defined in the Mainframe Analyzer itself, but can be changed by specifying different values in the Process Settings section of the Production tab in the Application editor:
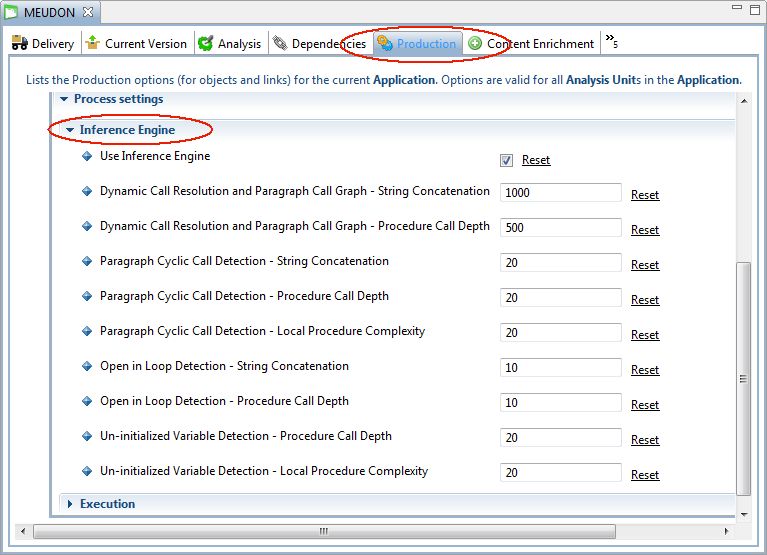
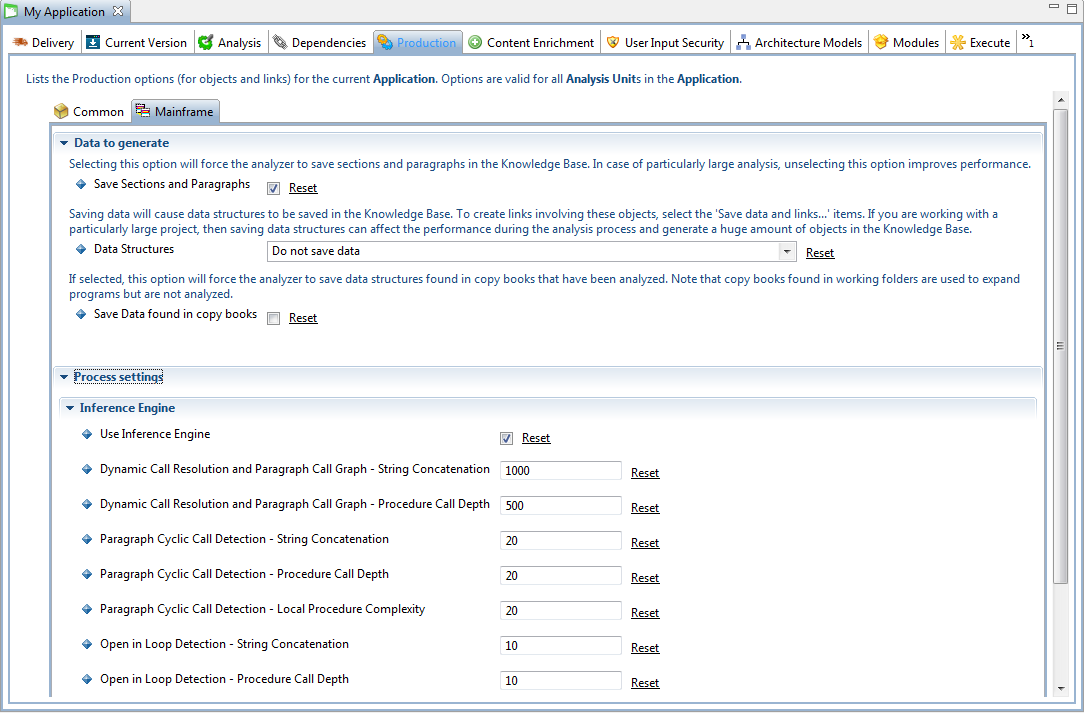
The main option allows you to deactivate the Inference Engine in the Mainframe Analyzer (by default the Inference Engine is always activated). This will directly impact the building of the paragraph call graph and dynamic call resolution operations. As such, CAST does not recommend deactivating the Inference Engine.
Other options are all related to COBOL technology. Note that their value must be greater than 0.
String Concatenation options
The String Concatenation options allow you to limit the number of different strings that will be found during the search of each object called dynamically. This can be associated to the different paths in the program logic leading to the variable use, in which a value is moved into the variable (see illustration below). As mentioned above, limiting the number of strings can lead to incomplete results but improves the performance of the Inference Engine. If you want to get more accurate results (if programs are too complex for the current settings), then you will have to accept a performance reduction. Nevertheless, this option should be changed in very rare occasions where a large number of objects can be dynamically called via the same CALL statement.
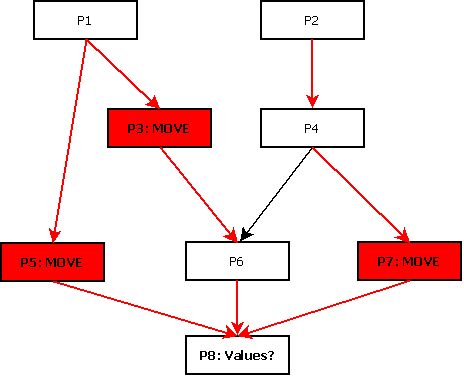
Possible values for a variable
Procedure Call Depth options
The Procedure Call Depth options are used to limit the number of steps that the Inference Engine will follow in order to obtain the value stored in a variable. These steps are parts of the control flow graph reduced to paragraph calls (see illustration below). The higher the number of potential steps the quicker the limit of this option is reached. As a consequence, some links to external objects (programs, CICS transactions, …) will not be drawn. However, increasing the value of this option will force the Inference Engine to follow lengthy paragraph call paths but will consume more time.
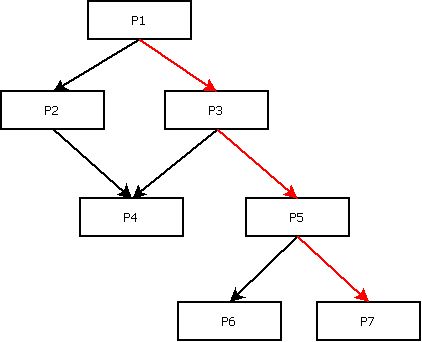
Paragraph call path
If you need to change the value for this option, then CAST recommends doing so in several iterations - by increasing the value by (for example) 10% each time.
General information about the Inference Engine
It is important to understand that there is no general rule regarding the tuning of the Inference Engine. It depends on the complexity of the logic implemented in programs and then each application has its own characteristics and requires specific settings. Nevertheless, what is certain is that changing the Inference Engine settings impacts both accuracy and performance. The table below shows an example of such changes with associated results for the analysis of a complex program:
| String Concatenation | 1000 | 1000 | 1000 | 1000 | 1000 |
| Procedure Call Depth | 500 | 1000 | 2000 | 2500 | 2800 |
| Analysis runtime (in seconds) | 75 | 83 | 86 | 92 | 103 |
| Dynamic links drawn | 4 | 9 | 17 | 28 | 32 |
The CyclicCall.*, OpenInLoop.*, and UninitialisedVariable.* options target the intermediary results calculation for the following Quality Rules, respectively:
- Avoid cyclic calls with PERFORM statements
- Avoid OPEN/CLOSE inside loops
- Variables defined in Working-Storage section must be initialized before to be read
These options can be tuned by respecting the above recommendations related to the LimitString and LimitSubTarget options. The CyclicCall options impact the size of cycles to be searched for, the OpenInLoop options impact the number of nested paragraph levels involved in loops, and the UninitialisedVariable options impact the size of the paths in the control flow in which variables can be assigned.
Before changing the settings of the Inference Engine, the first thing to do is to try to estimate the gain you expect versus the impact on the analysis performance. This is the case for applications with a small number of large and complex programs.
On completion of an analysis containing COBOL programs, the Mainframe Analyzer will display details in the log about the percentage success rate for the various link resolution operations carried out by each of the Inference Engine parameters, for all analyzed programs. This information will help you better configure the Inference Engine for future analyses.
For example, the following log output indicates that all the dynamic calls and the paragraph call paths have been resolved but that the detection of cyclical paragraph calls via the PERFORM instruction was only successful in 80% of the cases. As such, the CyclicCall.“String Concatenation” and CyclicCall.“Procedure Call Depth” values could be raised slightly.
COBOL dynamic call resolution and paragraph call graph :
- 100% on string concatenation
- 100% on procedure call depth
Paragraph cyclic calls detection :
- 80% on string concatenation
- 100% on procedure call depth
- 83% on local procedure complexity
Uninitialized COBOL variables detection :
- 100% on string concatenation
- 97% on procedure call depth
- 100% on local procedure complexity
OPEN in loop detection
- 100% on string concatenation
- 100% on procedure call dept
Extracting more information by using parameterization
The Mainframe Analyzer extracts information from source files “as is”. However, some objects and/or links are “hidden” by technical aspects such as specific tools or technical layers. It is possible to customize the analysis by using the parametrization engines that are available for COBOL and JCL. The rules you can define allow the extraction of more information from source code, if it is accessible.
Parameterization for COBOL
COBOL programs can use technical layers to call subprograms or to access data. These layers are generally implemented with technical programs and it necessary to decode their parameters to know the real targets of applicative programs. This allows to provide a more accurate technical documentation, to reduce the number of unreferenced components, and to improve the Fan-Out metric for calling programs.
The Mainframe Analyzer provides a parameterization engine for COBOL allowing to create links through technical subprograms and to deactivate “Use” links for specific statements. The parameterization rules are saved in an XML file (Parametrization_Cobol.xml) located in the “Configuration\Parametrization\Cobol” directory of the AIP Core installation. If you are using the Mainframe Analyzer extension, the Parametrization_Cobol.xml file is delivered with the extension itself and takes priority over the file delivered in AIP Core.
Note that if you upgrade to a newer release of the Mainframe Analyzer extension, and if you have modified the Parametrization_Cobol.xml file to add custom rules, you must ensure that you copy the file (or the rules) into the new extension installation location, e.g.:
- Current extension installation
location:
%PROGRAMDATA%\CAST\CAST\Extensions\com.castsoftware.mainframe.<version1>-funcrel\configuration\parametrization\Cobol - New extension installation location:
%PROGRAMDATA%\CAST\CAST\Extensions\com.castsoftware.mainframe.<version2>-funcrel\configuration\parametrization\Cobol
Two types of rules are available:
- Rules that allow the deactivation of “Use” links for specific statements
- Rules that allow the creation of links through a subprogram call
Deactivate “Use” links
You must specify the statement for which the analyzer must not create “Use” links and use the forbidLink action to do so:
Example:
<trigger signature="Statement.DISPLAY">
<actions>
<forbidLink/>
</actions>
</trigger>
Draw links through subprogram calls
You must specify the name of the subprogram to detect and use the addLink action to do so. Moreover, you must specify how to find the target name in the parameters, the object type of the target, and the type of link to create.
Example
Consider the following piece of code. It defines a data structure and two statements of the PROCEDURE division. This code calls a program named “COBRUN” and sends it 3 parameters. In fact, the code invokes a technical layer to call another application program. The technical layer is implemented by the program “COBRUN” and the application program that is called is “MYPROG”. The calling code must value the second data structure sent to the technical program with the name of the target.
01 COBRUN-STRUCT.
05 FIELD1 PIC XX.
05 FIELD2 PIC X(8).
05 FIELD3 PIC 99.
...
MOVE "MYPROG" TO FIELD2.
...
CALL "COBRUN" USING PARM1 COBRUN-STRUCT PARM3.
The link to the application program “MYPROG” can be created by using the following rule:
<trigger signature="COBRUN">
<variables>
Take the second parameter in USING clause:
<variable id="Parm" arg="2"/>
Take the expected part of the parameter containing the target name:
<variable id="Spg" expression="Parm(3:8)"/>
</variables>
<actions>
The action will create an Access Execute link to the program found in parameter:
<addLink
linkType="accessExecLink"
variable="Spg"
filterCategory="CAST_COBOL_Program"/>
</actions>
</trigger>
The rule must start with a signature that identifies the “technical” program to detect. The variables specify which parameter must be taken into account and it is also possible to define another variable in order to specify in which offset the target name can be found. The action specifies the link type to creare, which variable must be used to identify the target, and the type of the target.
In the example above, a first variable is used to get the second parameter of “COBRUN”, a second variable is used to get the offset in the first variable, starting at position 3 for 8 characters. The target must be searched among COBOL Programs by using the second variable and an “accessExecLink” must be created.
The target name must be accessible in the program scope. For instance, if the calling program is using a file or a database to identify the name of the target before calling it, then it will not be possible to apply the corresponding rule.
Parameterization for JCL- AdvancedJCL.xml
If you need to adapt the JCL analysis parameters, CAST provides a mechanism to do this using an XML file containing specific rules. Out of the box, a file called AdvancedJCL.xml is delivered in each release of AIP Core (located at the root of the installation) - this file contains a set of predefined rules to help you get started and to which additional rules can be added if necessary. The file at the root of the AIP Core installation is never taken into account during an analysis - it is provided purely as an example.
Starting 1.24 of AIP Console, it is possible to define an AdvancedJCL.xml per Application, i.e. so that you can configure different rules for specific Applications:
You will find below three examples of rules that you could add to the AdvancedJCL.xml to change the analysis behaviour:
Example 1
A procedure is called to run programs but this procedure has not been delivered. The program names are passed to the procedure through a parameter. Consider the following JCL lines:
//*-----------------------------------------------------------------
//SEXP050A EXEC *STEPPGM{*},{*}PROG{*}=SPP050
//STEPLIB DD DSN=LIBEX.DIV,DISP=SHR
//SYSOUT DD SYSOUT=*
//DDE1S DD DSN=AGSI.MQ10MESS.£E1SSM00,DISP=SHR
//*-----------------------------------------------------------------
The procedure invoked is “STEPPGM” and it is called with only one parameter named “PROG”. The parameter is used to send a program name to the procedure. The AdvancedJCL configuration should be:
<PROCEDURE>
<NAME>{*}STEPPGM{*}</NAME>
<COMMENT>Procedure used to run a program</COMMENT>
<PARAMETER>
<NAME>{*}PROG{*}</NAME>
<Link>CALL</Link>
</PARAMETER>
</PROCEDURE>
It is important to note that a procedure rule needs to specify some PARAMETER clauses. You must not use DDCARD clauses. Such a clause is used to identify a DD card and not a parameter.
Example 2
A specific utility is used to manage files via DD cards and it has not been taken into account yet. A utility can be technical software developed on site in order to carry out specific operations. It could be written in assembler and it would be impossible to analyze it via the Mainframe Analyzer. Consider the following JCL lines:
//STORE EXEC PGM=SPECUT,COND(0,NE)
//SYSOUT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//FILEIN DD DSN=&&TEMP,DISP=(OLD,DELETE,DELETE)
//FILEOUT DD DSN=MYTELCO.EMPDATA.VSAM,DISP=OLD
The utility is named SPECUT and it reads the file specified in the FILEIN DD card and writes the file specified in the FILEOUT DD card. The AdvancedJCL.XML configuration should be:
<PROGRAM>
<NAME>SPECUT</NAME>
<COMMENT>A Specific Utility</COMMENT>
<DDCARD>
<NAME>FILEIN</NAME>
<Link>READ</Link>
</DDCARD>
<DDCARD>
<NAME>FILEOUT</NAME>
<Link>WRITE</Link>
</DDCARD>
</PROGRAM>
Remark
The PROGRAM rule can have DDCARD clauses. They allow users to specify the resources used by the program/utility and which links the analyzer must create.
Example 3
A specific program launcher is used and it is not taken into account. It is important for us to create a link from the JCL step to the program which is really executed. Indeed, the launcher is not really of interest because it is only a technical program. Consider the following JCL lines:
//COBOLB1 EXEC PGM=PGMRUN,PARM=(PAR1,COBPGM,PAR3)
//IEFRDER DD DUMMY
//SYSTSPRT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSABOUT DD SYSOUT=*
//SYSDBOUT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
The launcher is named PGMRUN and it receives its parameters through a PARM clause. We are only interested in the second field of this parameter. It contains the name of the program which is going to be executed. The AdvancedJCL.XML configuration should be:
<PROGRAM>
<NAME>PGMRUN</NAME>
<COMMENT>A Program Launcher</COMMENT>
<PARAMETER>
<NAME>PARM</NAME>
<POSITION>2</POSITION>
<LINK>CALL</LINK>
</PARAMETER>
</PROGRAM>
The PROGRAM rule can also have PARAMETER clauses like the PROCEDURE rule. If the program which is going to be executed is in a multi-field parameter, then you must specify its position. The fist position is 1.
Summary
In short, the AdvancedJCL.XML file allows you to configure the analyzer to create:
- Call links from steps to programs through a missing procedure
- Call links from steps to programs through a program launcher (for instance, the IKJEFT01B DB2 program launcher)
- Call links from steps to programs (not only to COBOL programs)
- Use links from steps to PSBs
- Access links from steps to files through DD cards
- Access links from steps to files through embedded code
Use the various examples already implemented in the AdvancedJCL.XML file to create new rules. Note that it is possible to extract information from parameters containing several fields by specifying their index. For instance in previous AIP Core releases, it was necessary to modify the JCL source code for step running the IMS program launcher to split the PARM parameter into three elementary parameters.
The following card:
//STEP1 EXEC PGM=DFSRRC00,PARM='DLI,COBIMSB1,COBIMSB1'
Could not be analyzed just as it is and needed to be transformed to:
//STEP1 EXEC PGM=DFSRRC00,
// DLI='COBIMSB1',PSB='COBIMSB1'
Now, it is not necessary to modify these kind of cards. You can use the following parameter rule to extract this information:
<PROGRAM>
<NAME>DFSRC%</NAME>
<COMMENT>IMS Utility</COMMENT>
<PARAMETER>
<NAME>PARM</NAME>
<POSITION>2</POSITION>
<LINK>CALL</LINK>
</PARAMETER>
<PARAMETER>
<NAME>PARM</NAME>
<POSITION>3</POSITION>
<LINK>PSB</LINK>
</PARAMETER>
</PROGRAM>
If you want to identify a component enclosed between parentheses in a DD * card, then you must use the KEYWORD command and place a back slash before the first parenthesis in the detection pattern. If you do not insert the back slash, then the analyzer will not consider the parenthesis character correctly.
For example, the following rule allows the detection of a program name in the text “RUN PROGRAM(MYPROG)”:
<PROCEDURE>
<NAME>MYPROC</NAME>
<COMMENT>A Procedure</COMMENT>
<DDCARD>
<NAME>MYDDNAME</NAME>
<KeyWord>RUN PROGRAM{*}\({*}</KeyWord>
<Link>CALL</Link>
</DDCARD>
</PROCEDURE>.
The parameterization mechanism is not able, for the moment, to process the parameters which are external to JCL source files. This limitation will be removed in a future release. However, there is a workaround which can be used to extract information. The following JCL code calls the DB2 launcher by using internal parameters in the SYSTSIN DD card:
//JCLTEST JOB (8452200000),'COBTEST',CLASS=M,MSGCLASS=P,USER=JCH
//*
//PS10 EXEC PGM=IKJEFT01,
//STEPLIB DD DSN=ENV.APPL.LOADLIB,
// DISP=(SHR,KEEP,KEEP)
//SYSOUT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(DB2P)
RUN PROGRAM(COBTEST) PLAN(TESTPLAN) PARM('1')
END
//*
There is no problem to analyze it with the parameterization mechanism. Now take a look at the following code:
//JCLTEST JOB (8452200000),'COBTEST',CLASS=M,MSGCLASS=P,USER=JCH
//*
//PS10 EXEC PGM=IKJEFT01,
//STEPLIB DD DSN=ENV.APPL.LOADLIB,
// DISP=(SHR,KEEP,KEEP)
//SYSOUT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSTSIN DD DSN=ENV.APPL.PARMLIB(PARMTEST),
// DISP=(SHR,KEEP,KEEP)
//*
The parameters are externalized into the “PARMTEST” file which can be delivered separately:
DSN SYSTEM(DB2P)
RUN PROGRAM(COBTEST) PLAN(TESTPLAN) PARM('1')
END
The following workaround allows this type of external files to be processed for the DB2 launcher. You can use it to create other workarounds dedicated to specific utilities. It is based on four steps:
- Analyzing the JCL and the COBOL source files with the Mainframe Analyzer
- Analyzing the parameter files with an empty Universal Analyzer profile (it will create CDR file objects in the Analysis Service)
- Extracting links from the parameter files to the DB2 program via a Universal Analyzer Reference Pattern job by using the following regular expression (it must be adapted to each type of parameter file):
Begin: RUN +PROGRAM\(
Expression: [^\)]+
End: [\)]
- Extracting links from the JCL to the parameter file via a Mainframe Reference Pattern job by using the following regular expression (it must be adapted to each type of parameter file):
Begin: [\/][\/]SYSTSIN +DD +DSN=[^\(]+[\(]
Expression: [^\)]+
End: [\)]
The Universal Analyzer job parses parameter files which have a specific extension (in our example, this extension is “CDR” but it can be modified if needed) and it will create objects that have this extension in their name. On the other hand, the Mainframe Reference Pattern will look for parameter files which have a name without an extension. As such, it is important to temporarily remove this extension before running the Mainframe Reference Pattern job. This extension will be restored just after the execution of this job.